


















机器学习优化函数的直观介绍
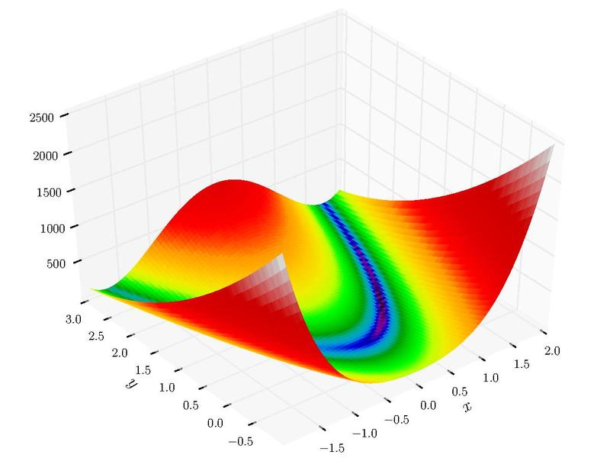
优化是机器学习的研究人员最感兴趣的领域之一。在本文中,我想从简单的函数优化开始介绍,然后讨论找到只能找到局部最小值或难以找到最小值的较为复杂的函数,约束优化和几何优化问题。我也希望使用完全不同的方法进行优化:从基于梯度的方法开始,并结合进化算法和其他深度学习的最新方法。当然,我们要使用机器学习应用程序来展示它们,而我目的是展示数值优化中的问题和算法,并让你理解AdamOptimizer()的原理。
我专注于将不同的算法行为可视化,以理解其背后的数学和代码的直觉,因此在这一系列文章中会有很多的GIF图。如零阶方法,在SciPy中的一阶方法,Tensorflow中的一阶方法,二阶方法。
源代码:https://github.com/Rachnog/Optimization-Cookbook/tree/master/chapter1
优化函数
首先,我们来定义数据集。我决定从最简单的那个开始,它应该很容易优化,并用不同的工具显示一般的演练。你可以访问下方链接获取的函数和公式的完整列表,在这里我只选取一部分。
完整列表:https://www.sfu.ca/~ssurjano/optimization.html
可视化教程:http://tiao.io/notes/visualizing-and-animating-optimization-algorithms-with-matplotlib/
Bowl函数(呈碗状的函数)
Bohachevsky函数和Trid函数
def bohachevsky(x,y):
return x ** 2 + 2 * y ** 2 -0.3 * np.cos(3 * 3.14 * x)-0.4 * np.cos(4 * 3.14 * y)+0.7
def trid(x,y):
return(x-1)** 2 +(y-1)** 2 - x * y
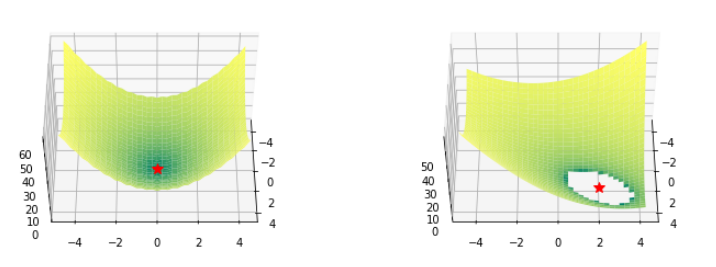
Bohachevsky函数(左)和Trid函数(在右边)
Plate函数(呈板状)
Booth、Matyas和Zakharov函数
def booth(x,y):
return(x + 2 * y - 7)** 2 +(2 * x + y - 5)** 2
def matyas(x,y):
return 0.26 *(x ** 2 + y ** 2) - 0.48 * x * y
def zakharov(x,y):
return(x ** 2 + y ** 2)+(0.5 * x + y)** 2 +(0.5 * x + y)** 4
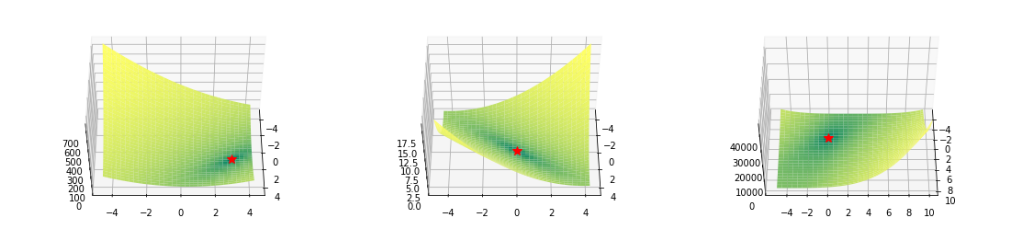
Booth(左),Matyas(中)和Zakharov(右)
valley函数(呈谷状)
Rozenbrock,Beale和Six Hump Camel函数
def rozenbrock(x,y):
return(1-x)** 2 + 100 *(y - x ** 2)** 2
def beale(x,y):
return(1.5 - x + x * y)** 2 +(2.25 - x + x * y ** 2)** 2 +(2.65 - x + x * y ** 3) ** 2
def six_hump(x,y):
return(4-2.1 * x ** 2 + x ** 4/3)* x ** 2 + x * y +(-4 + 4 * y ** 2)* y * * 2
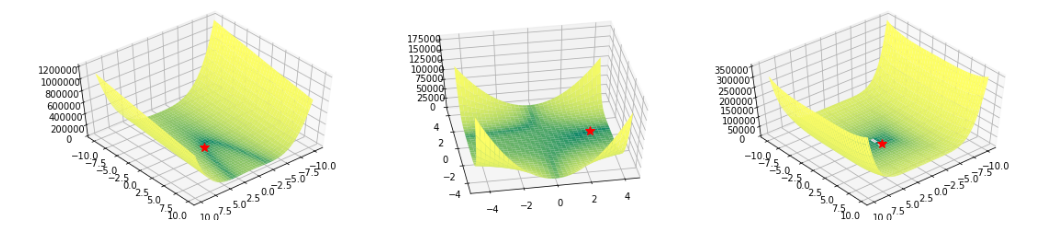
Rozenbrock(左),Beale(中)和Six Hump Camel(右)函数
算法
在这里,我们简单看一下SciPy和Tensorflow中优化的基本算法。
无梯度优化
通常我们的代价函数是嘈杂的或不可微分的,因此我们不能在这种情况下应用使用梯度的方法。在本教程中,我们比较了Nelder-Mead和Powell算法,它们不计算梯度。第一种方法构建(n + 1)维的单纯型(simplex),并在其上找到最小值,依次更新它。Powell方法在空间的每个基向量上进行一维搜索。使用SciPy实现如下:
minimize(fun ,x0 ,method ='Nelder-Mead' ,tol = None ,callback = make_minimize_cb )
callback用于保存中间结果(取自上方链接的可视化教程)。
一阶算法
你可能会从Tensorflow等机器学习框架中了解到这种算法。它们朝着反梯度的方向发展,得出函数的最小化。但这些算法移动到最小值的细节差别很大。我们使用Tensorflow来实现:梯度下降(有和没有),Adam和RMSProp。(完整代码在github中可以找到):
x = tf.Variable(8., trainable=True)
y = tf.Variable(8., trainable=True)
f = tf.add_n([
tf.add(tf.square(x), tf.square(y)),
tf.square(tf.add(tf.multiply(0.5, x), y)),
tf.pow(tf.multiply(0.5, x), 4.)
])
并按以下方式进行优化:
opt = tf.train.GradientDescentOptimizer(0.01)
grads_and_vars = opt.compute_gradients(f, [x, y])
clipped_grads_and_vars = [(tf.clip_by_value(g, xmin, xmax), v) for g, v in grads_and_vars]
train = opt.apply_gradients(clipped_grads_and_vars)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
points_tf = []
for i in range(100):
points_tf.append(sess.run([x, y]))
sess.run(train)
在SciPy中我们使用共轭梯度法,牛顿共轭梯度法,截断牛顿法,序贯最小二乘设计法。你可以阅读更多关于这些算法的更多信息可以阅读Boyd and Vandenberghe写的凸优化。
SciPy接口或多或少与零阶方法相同。
二阶算法
我们还将碰到一些使用二阶导数加速收敛的算法:dog-leg信赖域, nearly exact信赖域。这些算法顺序地解决搜索区域(通常是球状)被发现的局部最优问题。我们知道,这些算法需要Hessian(或它的近似),所以我们使用numdifftools库来计算它们并传入SciPy优化器:
from numdifftools import Jacobian, Hessian
def fun(x):
return (x[0]**2 + x[1]**2) + (0.5*x[0] + x[1])**2 + (0.5*x[0] + x[1])**4
def fun_der(x):
return Jacobian(lambda x: fun(x))(x).ravel()
def fun_hess(x):
return Hessian(lambda x: fun(x))(x)
minimize(fun, x0, method='dogleg', jac=fun_der, hess=fun_hess)
无梯度优化
在本文中,我希望优先从视觉角度评估结果,我认为用你的眼睛轨迹来观察是非常重要,这样公式会更加清晰。
以下是部分可视化(完整https://imgur.com/a/pFPyx)。
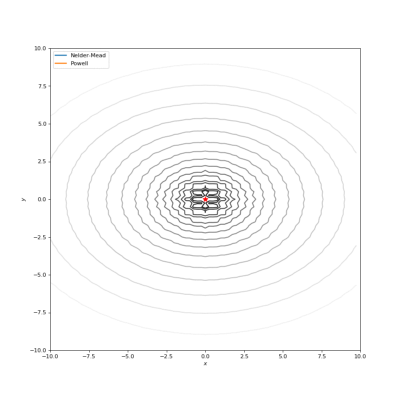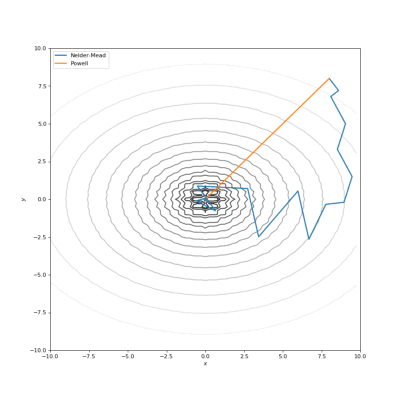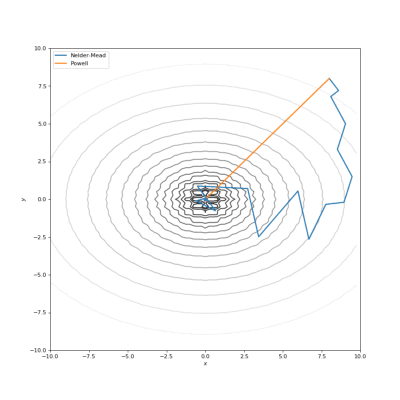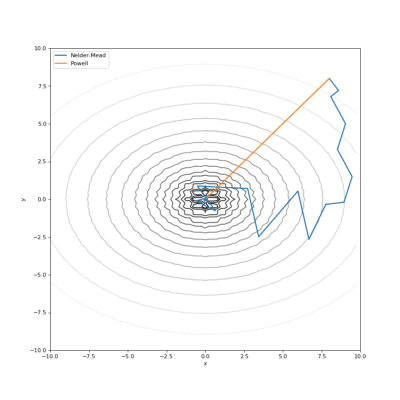
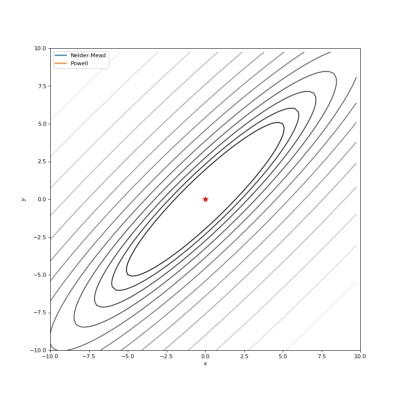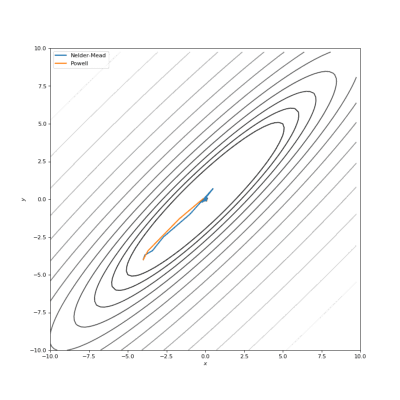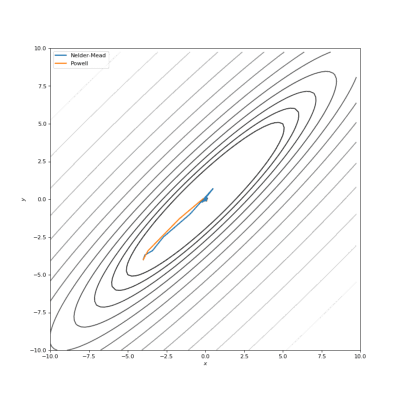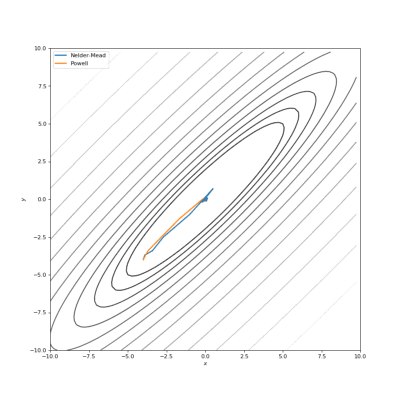
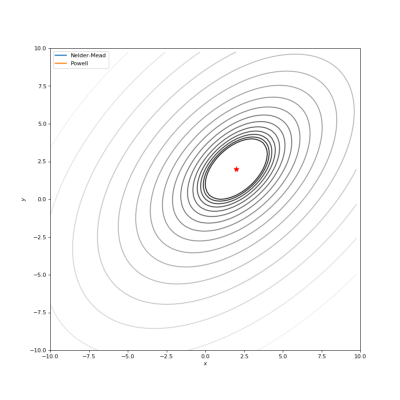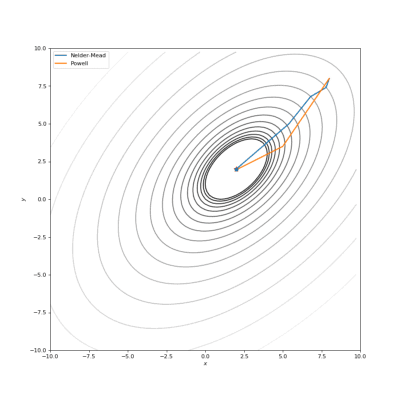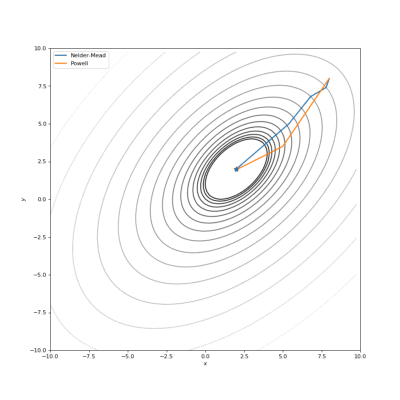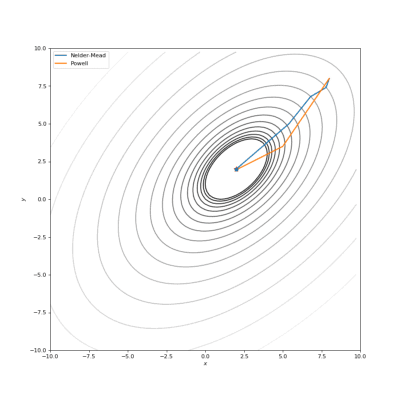
通过Nelder-Mead和Powell优化的Bohachevsky,Matyas和Trid函数
Jacobian优化
在这里你可以看到使用SciPy和Tensorflow的基于梯度方法的比较。其中一些算法可能看起来很“慢”,但这很大程度上取决于超参数的选择。
完整gif(imgur.com/a/cqN0Z,imgur.com/a/SWFwQ)
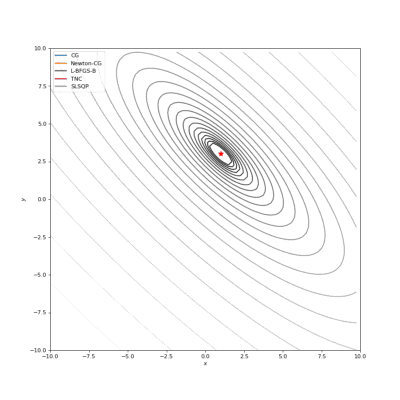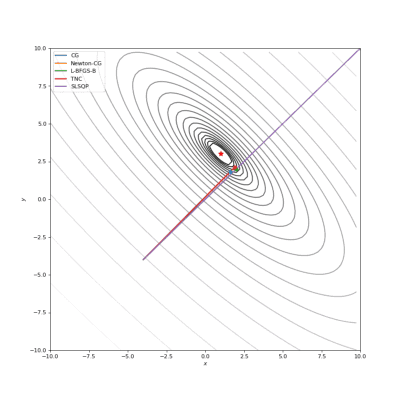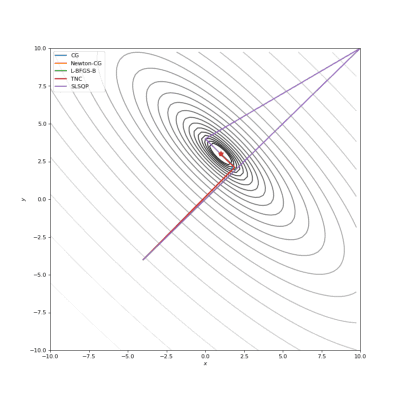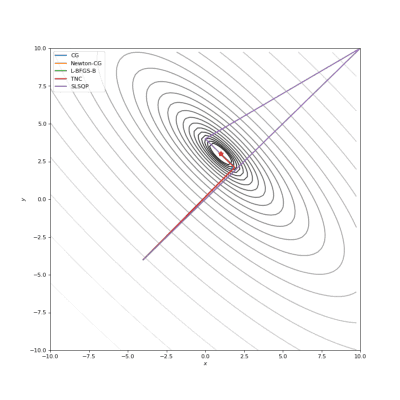
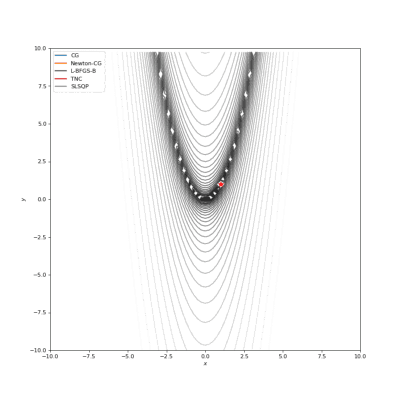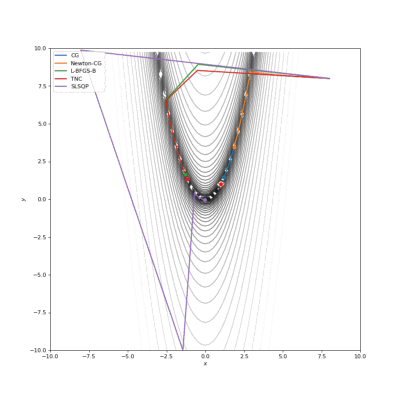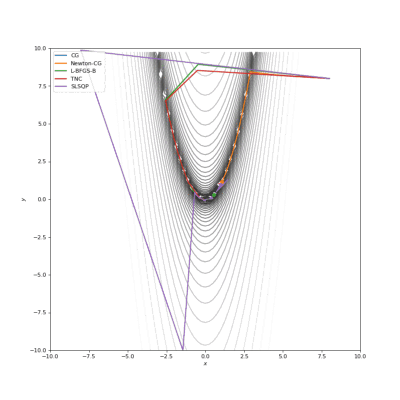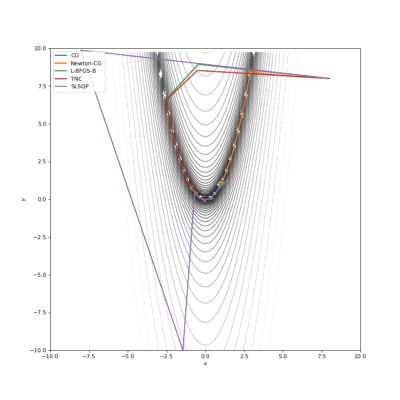
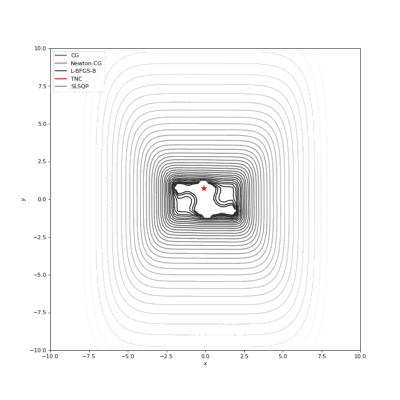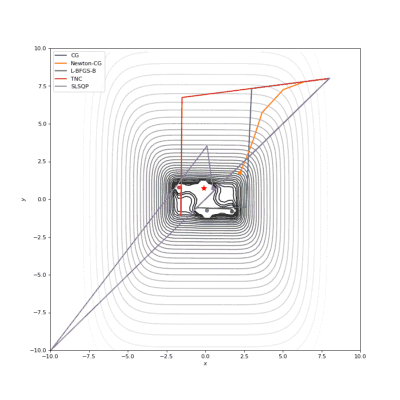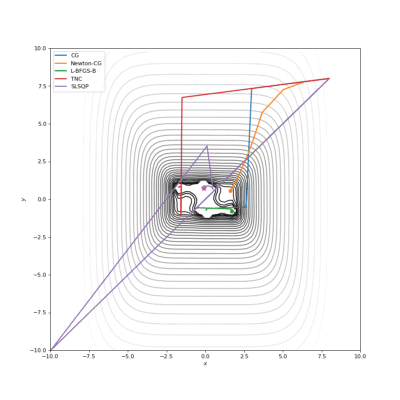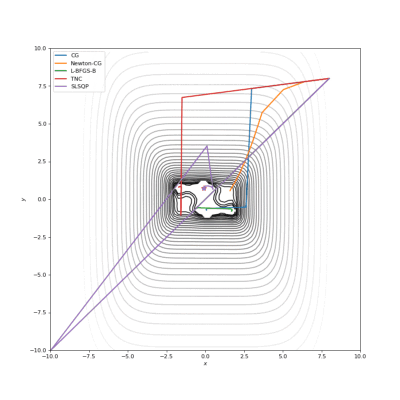
Booth,Rosenbrok和Six Hump函数(SciPy)
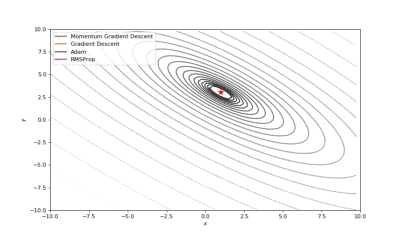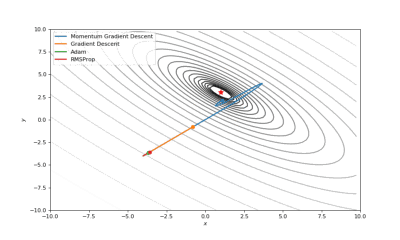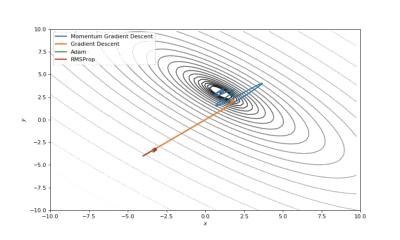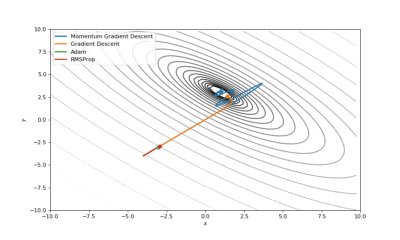
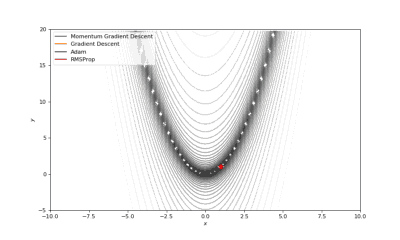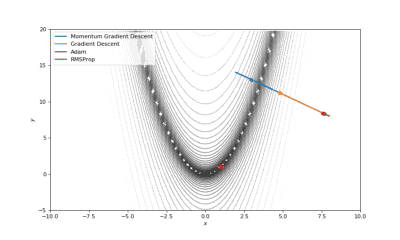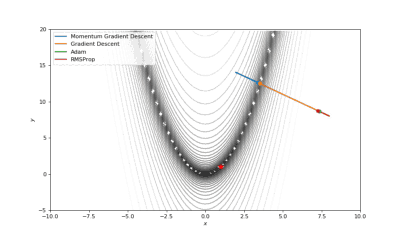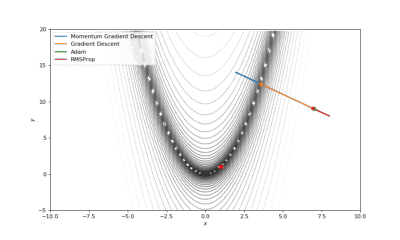

Booth,Rosenbrok和Six Hump函数(Tensorflow)
Hessian优化
使用二阶导数几乎立刻就能使我们得到很好的二次函数的最小值,但对于其他函数来说不像那样简单。例如对于Bohachevsky函数它接近最小值,但不精确。
其他函数的更多例子:https://imgur.com/a/PmyBq
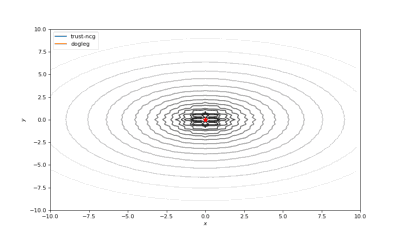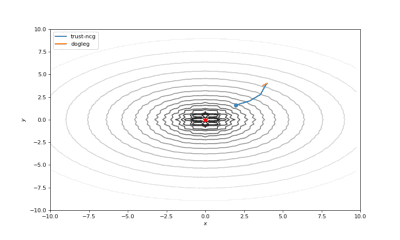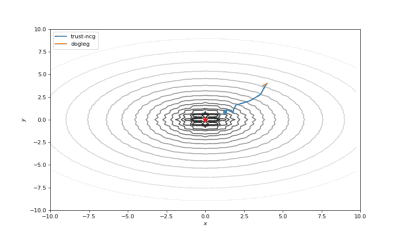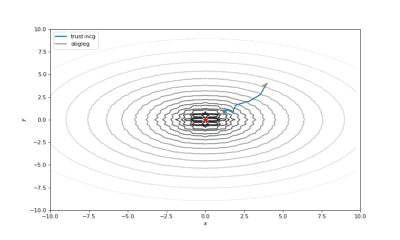
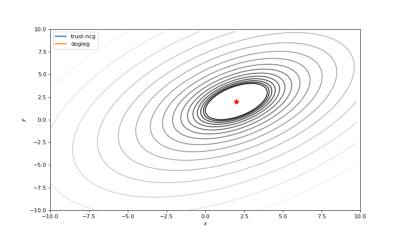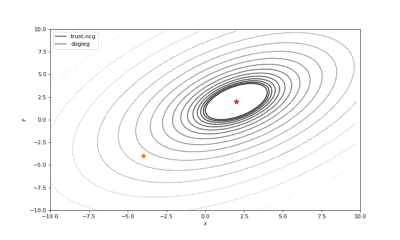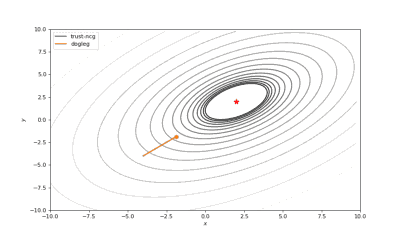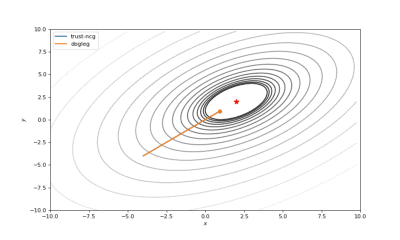
Bohachevsky,Matyas和Trid的函数优化轨迹线
超参数
学习率
首先,我想你已经注意到,像Adam和RMSprop这样流行的自适应算法与比SGD慢的多。但它们不是应该被设计成速度更快吗?这是因为这些损失曲面的学习率太低。参数必须分别针对每个问题进行调整。在下面的图片中,你可以看到如果将它的值增加到1会发生什么。
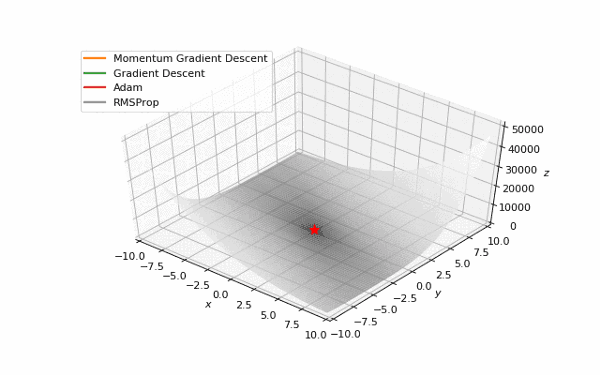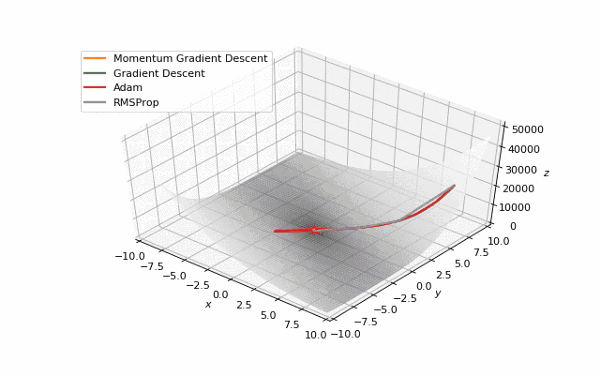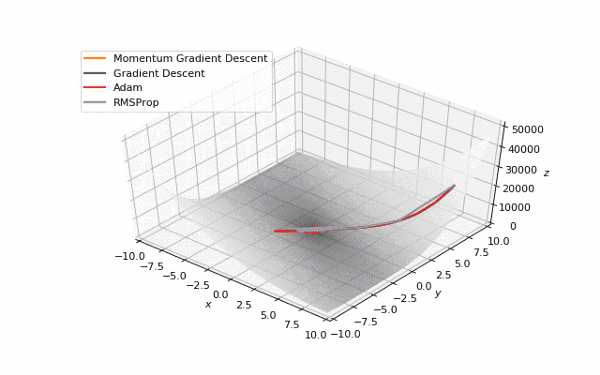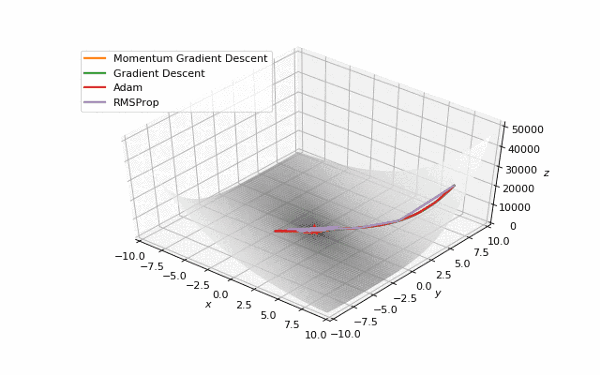
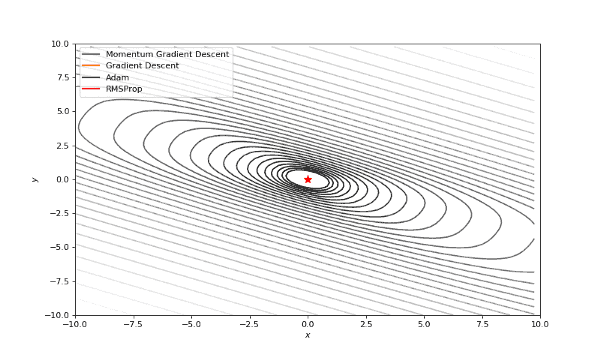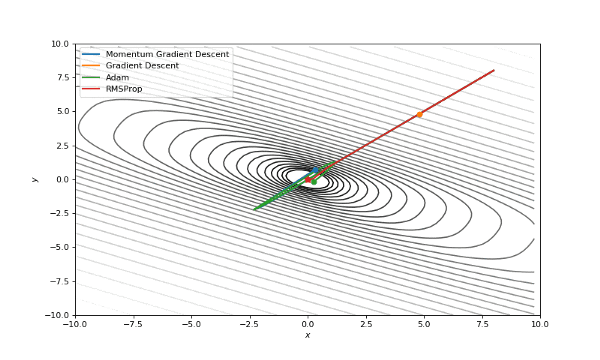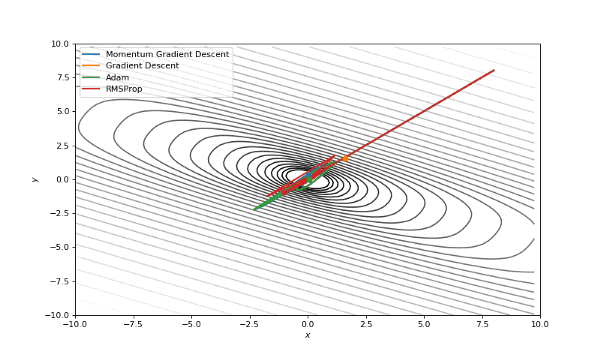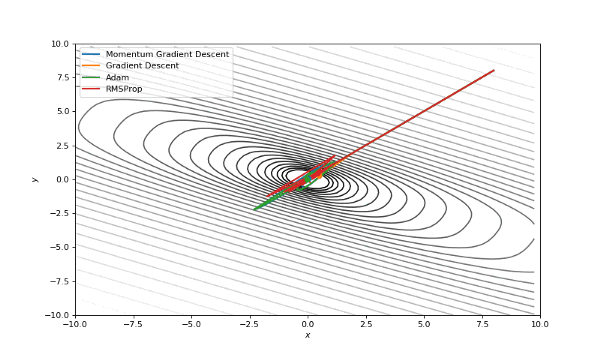
提高了学习率的Adam和RMSProp
起始点
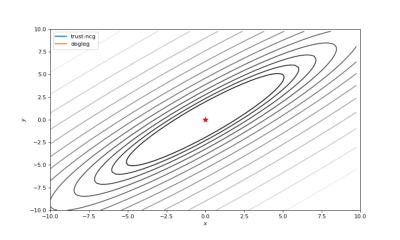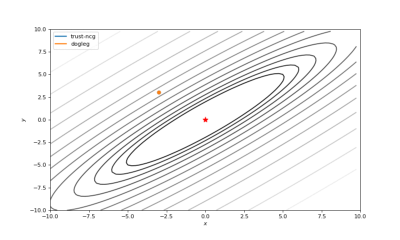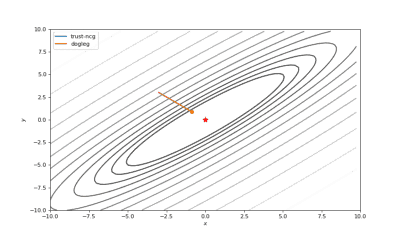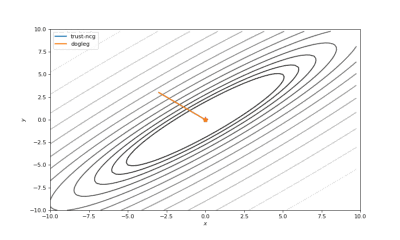
通常我们从一个随机点开始寻找最小值(或者像神经网络中的一些智能初始化块),但通常这不是正确的策略。在下面的例子中,我们可以看到,如果从错误的点开始,二阶方法甚至会发生偏移。在纯粹的优化问题中克服这个问题的方法之一是:使用全局搜索算法估计全局最小值的区域。
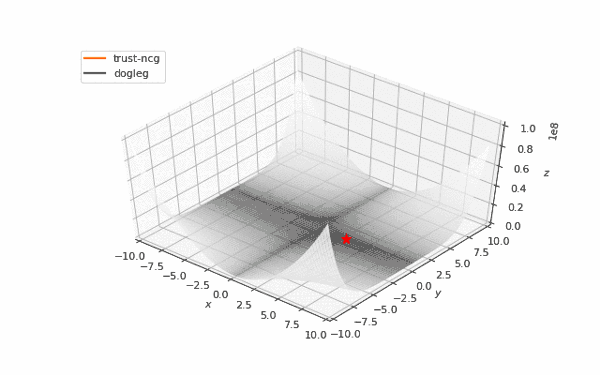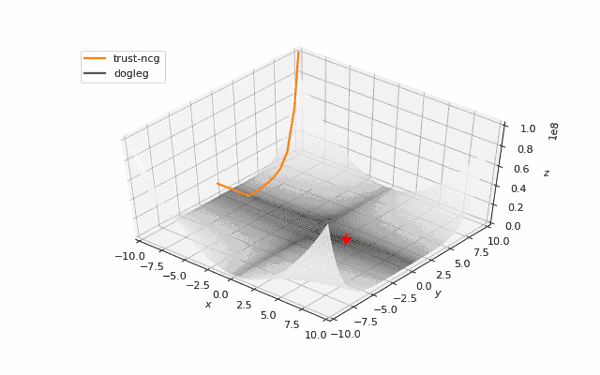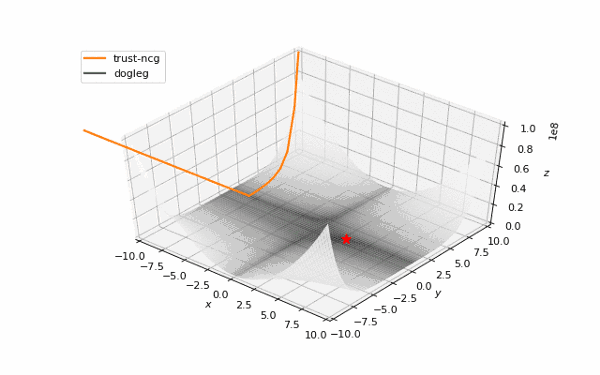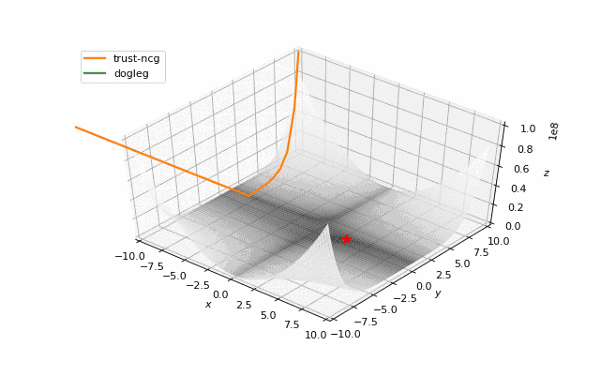
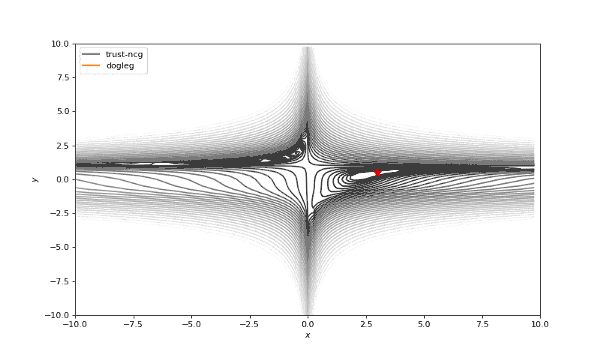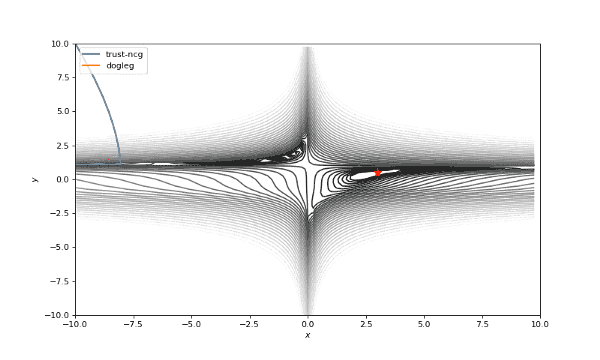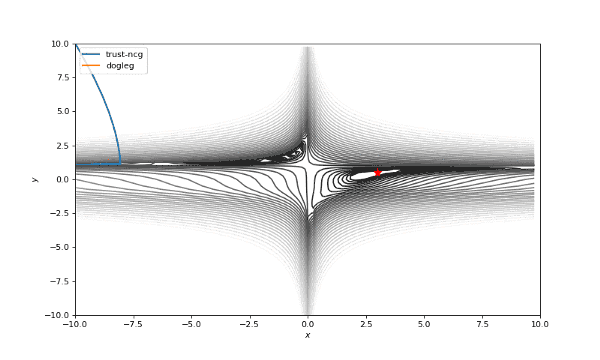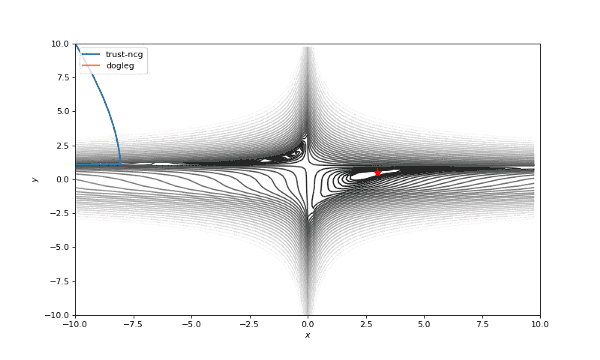
使用错误的起始点的二阶方法发生了严重的偏移
机器学习
现在你可能想要尝试使用SciPy中的算法来在Tensorflow中训练机器学习模型。你甚至无需构建自定义优化器,因为tf.contrib.opt已经为你准备好了!它允许使用相同的算法以及参数:
vector = tf.Variable([7., 7.], 'vector')
# Make vector norm as small as possible.
loss = tf.reduce_sum(tf.square(vector))
optimizer = ScipyOptimizerInterface(loss, options={'maxiter': 100}, method='SLSQP')
with tf.Session() as session:
optimizer.minimize(session)
结论
本文只是对优化领域的介绍,但从这些结果我们可以看出,这并不容易。使用二阶或自适应速率算法并不能保证我们收敛到最小值。现在你有一些直觉,了解所有这些算法的工作原理。
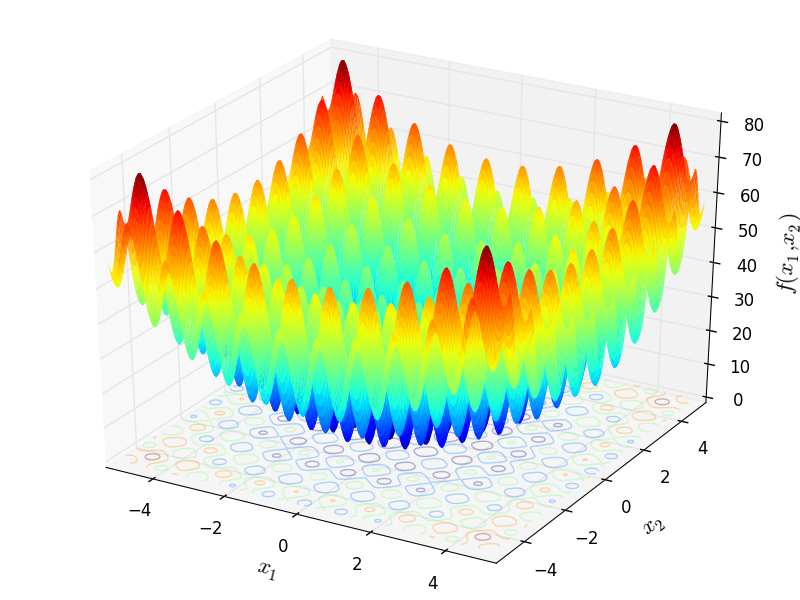
Rastrigin函数









