


















推荐算法的介绍,第一部分——协同过滤与奇异值分解

推荐系统是指能够预测用户未来偏好项目(item)并推荐最优先项目的系统。现代社会之所以需要推荐系统,是由于互联网的普及,人们有太多的选择可供使用。过去,人们习惯于在实体店里购物,而在实体店里商品是有限的。而互联网现在让人们可以在线获取丰富的资源。例如,网飞公司拥有大量的电影。然而,尽管可用信息的数量增加了,但因此人们很难选择他们实际想要看到的物品。所以才需要推荐系统。
过去的方法
传统构建推荐系统的方法有两种:
- 基于内容推荐
- 协同过滤
第一种分析每个项目的性质。例如,通过对每个诗人的内容进行自然语言处理来向用户推荐诗人。而协同过滤不需要关于项目或用户本身的任何信息。它根据用户过去的行为推荐项目。下面我将详细介绍协同过滤。
协同过滤
如上所述,协同过滤(CF)根据用户过去的行为的推荐。有两类协同过滤:
- 基于用户:衡量目标用户与其他用户的相似度
- 基于项目:衡量目标用户评分与其他项目之间的相似度
协同过滤背后的关键思想是,相似的用户拥有相同的兴趣,喜欢的项目也类似。
假设有m个用户和n个项目,我们使用一个大小为m * n的矩阵来表示用户过去的行为。矩阵中的每个单元格表示用户拥有的相关意见。例如,M_ {i,j}表示用户i有多喜欢项目j。这种矩阵被称为效用矩阵。协同过滤类似于根据用户或项目之间的相似度,填充用户之前未见过或评估过的效用矩阵中的空白(单元)。在这里的“意见”有两种,明确的和隐含的。前者直接显示用户如何评价这个项目(就想对APP或电影的评分),而后者仅作为代理提供我们关于用户如何喜欢项目的猜测(例如可能表示用户喜欢的数字,点击、访问等)。显性意见比隐性意见更直接,因为我们不需要猜测这个数字意味着什么。举例来说,用户可能很喜欢一首歌曲,但他只听了一次,因为他听歌时很忙。没有明确的意见,我们不能确定用户是否喜欢那个项目。但是,我们从用户收集的大部分反馈都是隐性的。因此,正确处理隐性反馈非常重要,但这里我们先不略过它,继续讨论协同过滤如何工作。
基于用户的协同过滤
我们知道我们需要计算用户协同过滤中的用户之间的相似度。那么如何衡量相似度呢?可以使用皮尔森相关(Pearson Correlation)或余弦相似度(cosine similarity)。令u_ {i,k}表示用户i和用户k之间的相似度,v_ {i,j}表示用户i给予项目j的评分,v_ {i,j} =?如果用户还没有评价该项目。这两种方法可以表述如下:
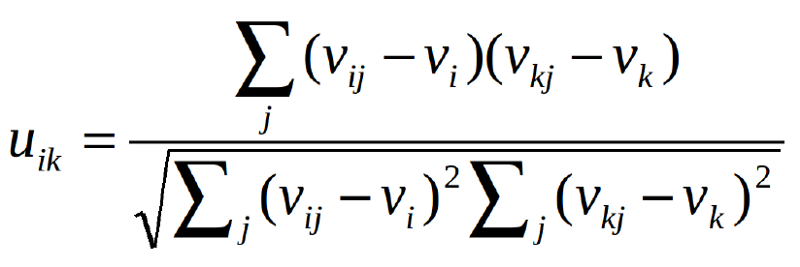
皮尔森相关
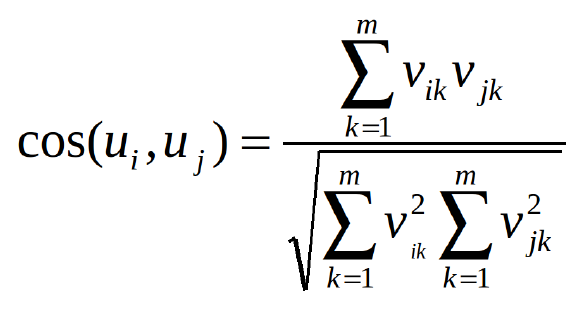
余弦相似度
这两种方法都很常用。不同之处在于,皮尔森相关性是不变的,为所有元素添加一个常量。
现在,我们可以用下面的公式来预测用户对未打分项目的意见:
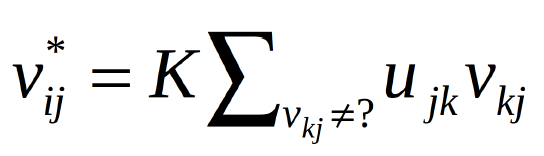
未打分项目预测
下面我来举个例子进行说明。在下面的矩阵中,每行代表一个用户,除了最后一列记录用户和目标用户之间的相似度之外,每列对应于不同的电影。每个单元格表示用户给该电影的评分。假设我们的目标用户是E。
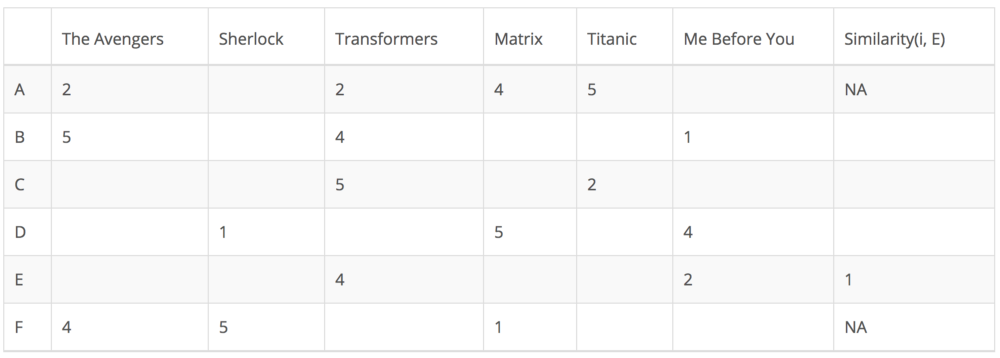
由于用户A和F没有与用户E对电影评分没有交集,所以它们与用户E的相似度未在皮尔森相关中定义。因此,我们只需要考虑用户B,C和D.基于皮尔森相关,我们可以计算相似度如下。
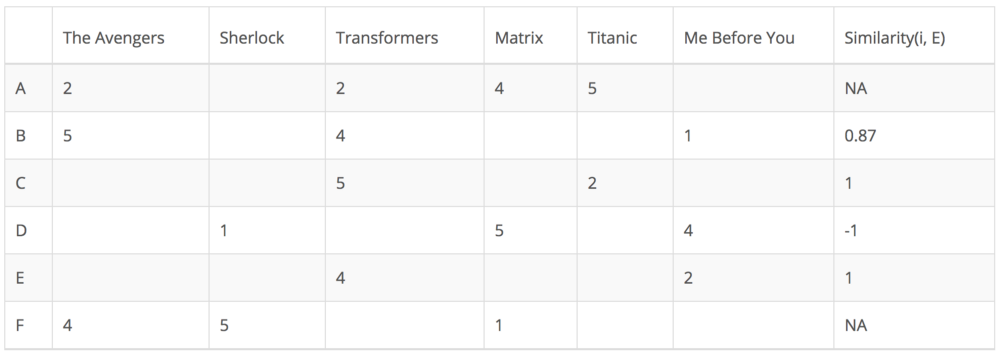
从上表可以看出,用户D与用户E差异很大,因为它们之间的皮尔森相关是负的。他认为电影“Me Before You”值得高分,而用户E则相反。现在,我们可以开始根据其他用户的评分填充用户E未评级电影的空白。
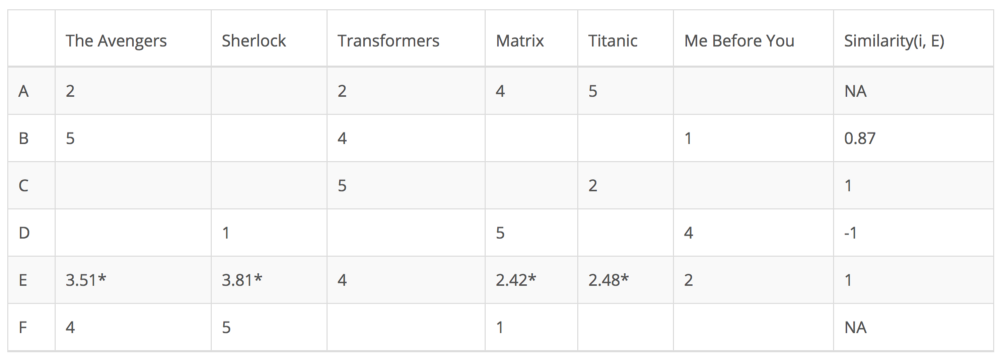
虽然基于用户的协同过滤计算非常简单,但也存在一些问题。用户的偏好可能会随着时间而改变。这表明,根据相似用户的预计算矩阵可能导致性能不佳。为解决这个问题,我们可以应用基于项目的协同过滤.
基于项目的协同过滤
基于项目的协同过滤不去衡量用户之间的相似性,而是根据它们与目标用户评价的项目的相似度来推荐项目。同理,相似度可以用皮尔森相关和余弦相似度来计算。主要区别在于,基于项目的协同过滤,我们垂直填充空白,这与基于用户协同过滤的水平方式相反。以电影“Me Before You”为例:
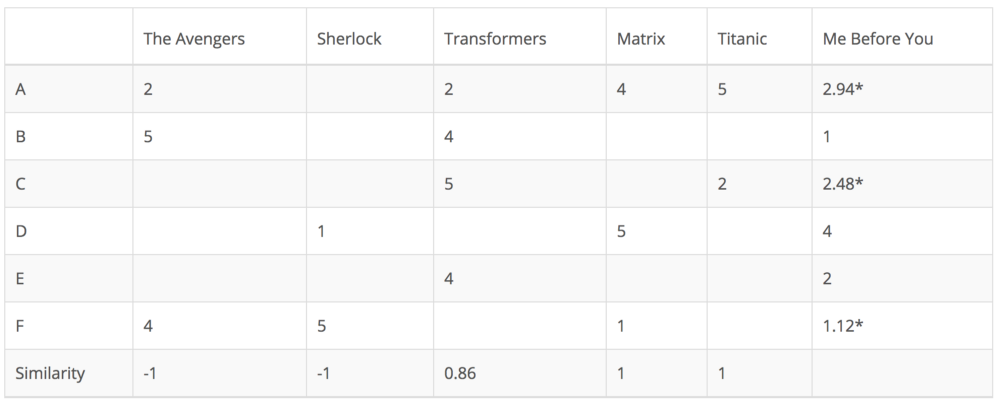
它成功地避免了动态用户偏好所带来的问题,因为基于项目的协同过滤更加静态。但是,这种方法仍然存在一些问题。首先,主要问题是可扩展性。计算量随客户和产品一起增长。最糟糕的情况是m个用户和n个项目时复杂度为O(mn)。此外,稀疏是也是一个问题。再看一下上面的表格。虽然只有一个用户同时评价“Matrix”和“Titanic”,但它们之间的相似度是1.在极端情况下,我们可以有数百万用户,两个相当不同的电影之间的相似度可能非常高,因为唯一评价他们两个的用户评价相似。
奇异值分解
处理协同过滤的可伸缩性和稀疏性问题,可以利用潜在因子模型来捕捉用户和项目之间的相似度。从本质来说,我们希望将推荐问题转化为优化问题。我们可以把它看作是对我们在预测给定用户的项目评分的评分。一个常见的度量是均方根误差(RMSE)。RMSE越低,效果越好。由于我们不知道未知项目的评级,我们暂时忽略它们。也就是说,我们只是最小化效用矩阵中已知项目的RMSE。为了实现最小的RMSE,采用了奇异值分解(SVD),如下公式所示:
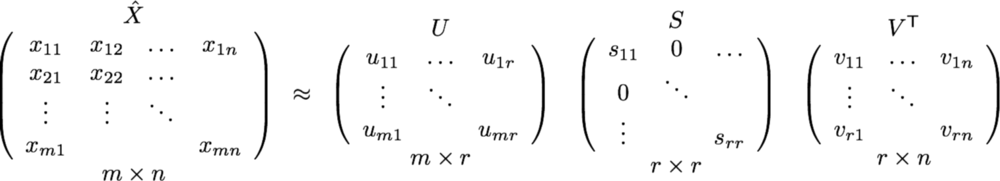
奇异值分解矩阵
X表示效用矩阵,U是左奇异矩阵,表示用户与潜在因子之间的关系。S是描述每个潜在因子强度的对角矩阵,而VT是一个右奇异矩阵,表示项目与潜在因子之间的相似度。那么,这里的潜在因子是什么意思?它是一个宽泛的概念,它描述了一个用户或项目拥有的属性或概念。例如,对于音乐而言,潜在因子可以指音乐所属的类型。SVD通过提取其潜在因子来降低效用矩阵的维度。从本质上讲,我们将每个用户和每个项目映射到维度为r的隐空间(latent space)。它可以帮助我们更好地理解用户和项目之间的关系,因为它们可以直接进行比较。如下图所示:

奇异值分解映射用户和项目到隐空间
奇异值分解很重要的一个性质是,能够最小化重构误差平方和(SSE); 因此它也常用于降维。下面的公式用A代替X,用Σ代替S:
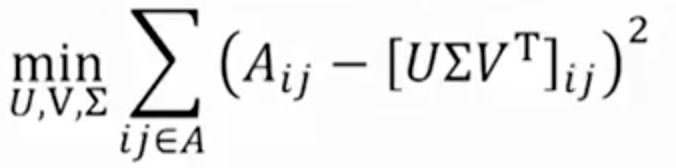
均方误差的和
但是这和RMSE有什么关系呢?事实证明,RMSE和SSE是单调相关的。这意味着SSE越低,RMSE越低。利用SVD的使SSE最小化,它也会使RMSE最小化。因此,SVD解决这个优化问题的好工具。为了预测用户看不见的项目,我们乘以U,Σ和T。
Python中的Scipy对于稀疏矩阵具有很好的SVD实现。
>>> from scipy.sparse import csc_matrix
>>> from scipy.sparse.linalg import svds
>>> A = csc_matrix([[1, 0, 0], [5, 0, 2], [0, -1, 0], [0, 0, 3]], dtype=float)
>>> u, s, vt = svds(A, k=2) # k is the number of factors
>>> s
array([ 2.75193379, 5.6059665 ])
SVD成功处理了协同过滤所带来的可扩展性和稀疏性问题。但它也有自己的缺陷。SVD的主要缺点是,我们向用户推荐某个项目的原因是无法解释的。如果用户很想知道为什么向他们推荐特定的项目,这可能会是很大的问题。关于这一点,我会在下一篇文中详细讨论。
结论
我已经讨论了用于建立推荐系统的两种典型方法:协同过滤和奇异值分解。在接下来的文章中,我将继续讨论构建推荐系统的更高级的算法。









