











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






苹果发布了应用于Apple Music和Apple Watch心跳活动模式的机器学习系统
2018年01月26日 由 nanan 发表
195097
0
1月25日,美国专利商标局公布了苹果专利申请,此专利涉及机器学习。更具体地说,苹果的发明涵盖了服务器生成多个应用程序供客户端设备使用的多个代理预测模型的系统和方法。
提供一个基于数据分布的预测模型,该模型与客户端设备实际用户的用户私有数据更接近,可以提高预测的准确性,并提高客户端设备用户的收益。多个预测模型由服务器生成,并提供给多个客户机。对于特定的应用程序,客户端设备可以使用以前收集的私有用户数据来选择应用程序的多个预测模型中的一个,作为一个特定用户使用的最接近的匹配预测模型。
在对机器学习的概述中,苹果注意到传统的机器学习依赖于从大量的用户样本收集大数据集和训练预测模型。该预测模型被训练为在训练数据集上实现最高的预测精度,但通常需要考虑到特定用户的个人数据,从而为个人用户进行个性化。
例如,一种手写识别算法,它适用于特定用户的写作风格,或者是针对特定用户的心跳或活动模式进行调整或校准的健康传感器算法。
这是苹果公司在专利声明中的重点,机器学习与传感器结合使用。Moe特别指出:“其中一个或多个传感器组成了包括一个心率监测器的健康传感器。”
苹果进一步指出:“语音识别子系统可能需要针对特定用户的语音模式或变化进行调整。”这也是苹果公司专利声明的一个焦点。
苹果公司宣称:“用户预测模型将语音识别模块校准为用户的语音识别模块,其中用户预测模型包含了特征向量,而特征向量包含了一种语言,即用户所使用的语言、混合频率的感知器系数,以及深层神经网络的激活。”
在苹果的专利申请中,他们表示:“其中,用户预测模型预测的是:用户在应用程序中撰写或编辑文本的主题内容,用户预测模型向应用程序中的用户提出了单词或短语;或者是媒体类型的流派或艺术家来向用户展示,并且该模型在应用程序中建议或播放媒体项目。
苹果进一步指出,“音乐建议子系统是针对特定用户的口味、偏好和收听模式量身定制的”。这可能在苹果音乐中使用的,并可能与苹果的Home Pod一起使用。
苹果公司接着解释说,在现有的技术中,用于增强特定用户体验的机器学习只能通过特定用户的数据在客户端设备上进行训练。仅使用设备数据进行训练,可以保证训练时间的准确性。机器学习算法通常需要在机器学习之前收集大量的数据,以产生合理准确的预测模型。在某些情况下,例如测量用户身体的一个或多个属性的健康传感器,传感器可能需要在收集到的数据,被机器学习算法用于为该用户生成客户端设备的预测器之前,对该人员进行校准。对一个特定的人进行传感器的校准可能是侵入性的,非常私人的,而且是耗时的,因此用户不希望采取此方法。
另一种生成机器学习预测模型的方法可以用来增强用户的设备体验,其中包括一个服务器系统收集大量的众包数据,这些数据可以用来生成一个或多个预测模型。这种训练预测器的方法收集用户的个人数据,可能侵犯隐私,即使收集的信息是不确定的。如果维护隐私,那么使用众包数据的训练预测器的另一个问题是:服务器不知道的是,在多个预测模型中应用哪个预测模型,例如,音乐首选项,特定的客户端应该使用哪一个。维护隐私意味着确保服务器不能识别特定的客户端。如果服务器无法识别特定的客户端(例如隐私限制),那么服务器无法为客户端设备提供个性化的预测模型,以增强用户的设备体验。
苹果公司的专利涵盖了通过在客户端设备上为多个应用程序提供多个预测模型来增强用户体验的系统和方法。提供一个与客户端设备实际用户更接近的预测模型,可以提高机器学习预测模型的速度和准确性。
这项发明将在苹果公司的各种设备上使用,包括Apple TV和entertainment systems,这些设备可能指的是苹果未来的娱乐内容服务。
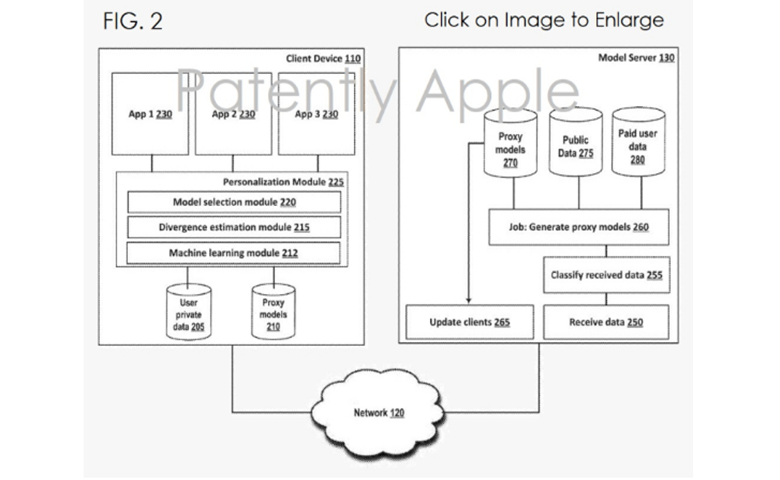
苹果公司的专利图(图2)以框图的形式展示了用于学习客户端所使用的代理模型系统的详细视图,同时保护了客户隐私。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消