











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Meltdown漏洞和KPTI补丁如何影响机器学习性能?
2018年01月20日 由 xiaoshan.xiang 发表
801016
0
在2018年初,互联网领域发现了两大系统漏洞,影响了主要的处理器厂商,这两大漏洞分别是“Meltdown(熔断)”和“Spectre(幽灵)”。这些漏洞是处理器前瞻执行的的漏洞,它允许攻击者读取其各自进程之外(以及潜在的执行)的内存位置,这意味着程序可以在其他软件的内存中读取敏感数据。
为了修复漏洞,Linux内核合并了一个名为KAISER或PTI(页表隔离page table isolation)的补丁,有效地修复了Meltdown攻击。然而,这一补丁会导致性能下降,CPU性能下降了5%到35%(甚至有一些复合基准程序显示了性能下降> 50%)。
然而,PTI性能问题很大程度上取决于当前的任务——这样的大幅下降可能只存在于诸如FSMark这样的复合基准程序中。所以问题是:我们在机器学习应用程序中会看到什么样的性能影响?
为了对比有PTI和没有PTI的性能差异,我安装了一个全新的带有英特尔微码的Ubuntu 16.04机器,并将最新的内核安装在ubuntu16.04(4.10.0 - 42- generic)上,并与最新的具有PTI补丁的主线内核版本(4.15.0 - 041500rc6- generic)进行了比较。我使用了Python 3.6版本(以及来自pip的额外软件包)的Anaconda来执行测试。
我用来测试的装备包括一个英特尔酷睿i7 - 5820k(处理器,股票时钟)和64GB的DDR4 @ 2400MHz。
注意:AMD处理器没有激活PTI补丁,因为他们对 Meltdown攻击免疫,所以如果你在AMD,就不存在性能受到影响的情况。
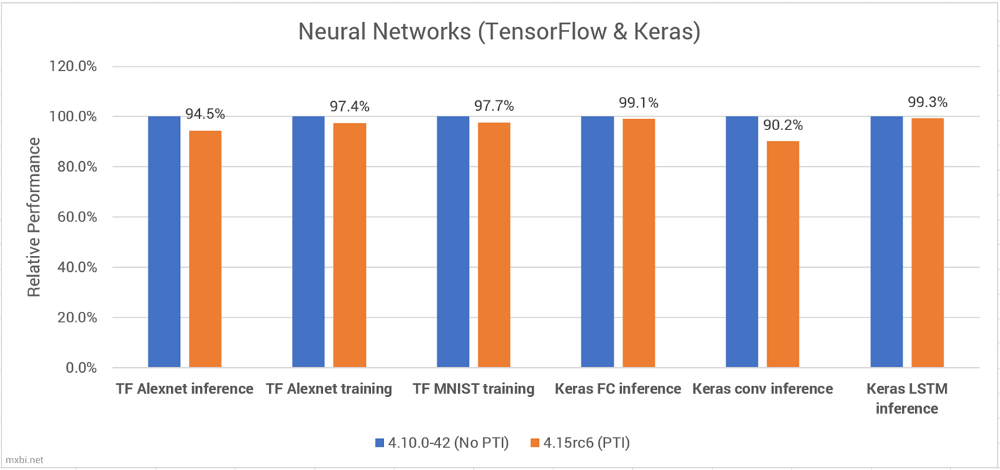
首先,我们看到所有的性能都有轻微的下降,但是对于具有卷积层的模型的推论却大大减少了。特别是在AlexNet中,正向传递速度下降了大约5%,但是反向传播速度几乎是相同的——这就是为什么训练受到的性能影响大约是推理的一半。
在使用Keras的原始操作方面,完全连接和LSTM层几乎没有性能影响,但是卷积下降了10%。
对于Alexnet和MNIST的基准测试,我使用了TensorFlow教程模型,而对于Keras,我使用了一个随机初始化模型和几个有问题的层,并测量了随机数据的推理速度。值得注意的是,这些基准测试完全在CPU上运行。
TensorFlow教程模型地址:https://github.com/tensorflow/models/tree/master/tutorials/image
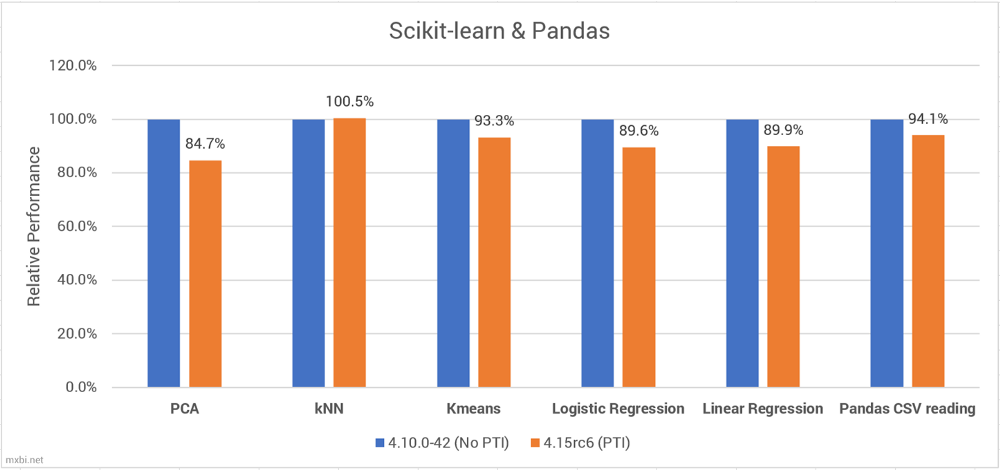
我在这里使用Scikit-learn来衡量“经典”机器学习和数据科学算法的性能。在这里,我们看到神经网络性能降低更大,用主成分分析和线性/ 逻辑回归受到的影响可能最大。造成这种减少的原因可能是由于一些数学问题受到了严重的影响——正如下面的NumPy基准所讨论的那样。
有趣的是,KNN完全不受PTI影响,实际上在更新的内核中表现得稍微好一些。这可能只是在误差范围内,但是其他的内核改进可能会稍微加快它的速度。
我还从内存中缓存的文件中提取了一个pandas.read_csv()的基准,以查看PTI降低了多少CSV解析速度 - 阅读博世Kaggle竞争数据集(2GB,1M行,1K列,浮点数, 80%缺失)。
博世Kaggle竞争数据集地址:https://www.kaggle.com/c/bosch-production-line-performance
所有scikit-learn基准都是在博世数据集上计算的——我发现它通常在机器学习基准测试上表现很好,因为它的数据是有大型的、标准化的和格式良好的(尽管KNN和Kmeans是在一个子集上计算的,但完整的数据可能花费的时间太长)。
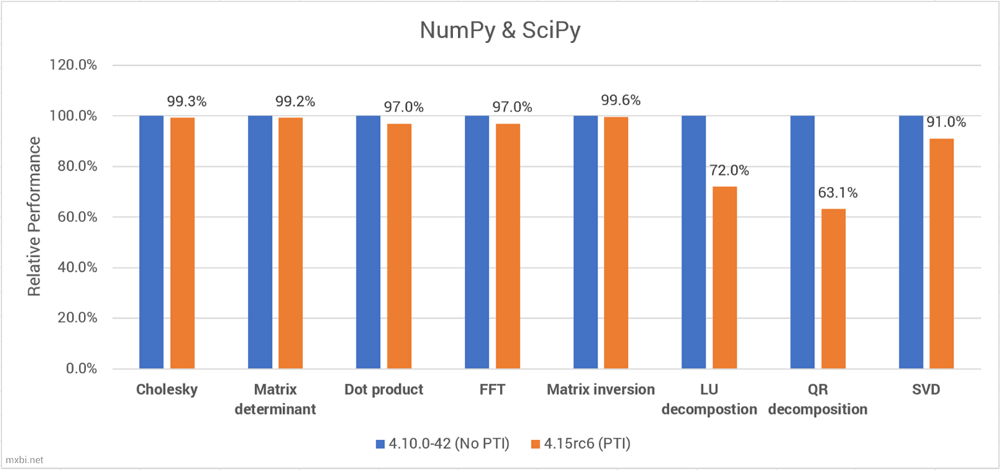
在这里,这些基准测试可能是合成的,测试单一的scipy操作的速度。这些结果告诉我们,PTI的性能影响是非常依赖于任务的。在这里,我们可以看到,大多数操作仅受到轻微的影响,点积和FFT的性能影响很小。
当PTI启用时,SVD、LU分解和QR分解的性能都受到了巨大的影响,QR分解从190GFLOPS降到110GFLOPS,下降了37%。这可能有助于解释PCA(严重依赖于SVD)和线性回归(严重依赖于QR分解)的性能下降。
这些基准是使用英特尔自己的ibench包完成的——使用了Anaconda,而不是英特尔的python发行版。
ibench包地址:https://github.com/IntelPython/ibench
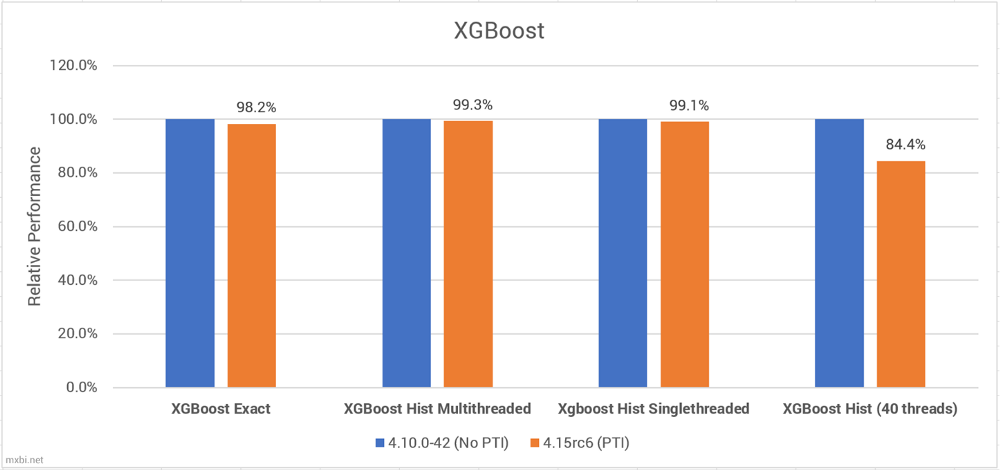
XGBoost的结果很有趣。在大多数情况下,当使用低数量的线程时,XGBoost在PTI上的性能会下降,无论使用的是慢的精确的方法还是快速直方图方法。
然而,当使用非常多的线程时,CPU同时处理更多的列,使用PTI的速度断崖式降低。
这并不是如何让XGBoost在大量内核上执行的完美表达(因为在12个逻辑内核上运行了40个线程),但是它给出了一个提示:当CPU同时处理许多事情时,PTI会产生更大的影响。不幸的是,我无法访问任何可以修改内核的高内核服务器,因此我无法得到更深入的结果。
和scikit-learn一样,这些基准是在Bosch数据集上管理的。
可以看出,PTI的性能影响是非常依赖于任务的——有些任务是不受影响的,有些任务的性能下降了40%。总的来说,我认为影响比我预期的要小,因为只有少数应用程序受到严重影响。
为了修复漏洞,Linux内核合并了一个名为KAISER或PTI(页表隔离page table isolation)的补丁,有效地修复了Meltdown攻击。然而,这一补丁会导致性能下降,CPU性能下降了5%到35%(甚至有一些复合基准程序显示了性能下降> 50%)。
然而,PTI性能问题很大程度上取决于当前的任务——这样的大幅下降可能只存在于诸如FSMark这样的复合基准程序中。所以问题是:我们在机器学习应用程序中会看到什么样的性能影响?
安装
为了对比有PTI和没有PTI的性能差异,我安装了一个全新的带有英特尔微码的Ubuntu 16.04机器,并将最新的内核安装在ubuntu16.04(4.10.0 - 42- generic)上,并与最新的具有PTI补丁的主线内核版本(4.15.0 - 041500rc6- generic)进行了比较。我使用了Python 3.6版本(以及来自pip的额外软件包)的Anaconda来执行测试。
我用来测试的装备包括一个英特尔酷睿i7 - 5820k(处理器,股票时钟)和64GB的DDR4 @ 2400MHz。
注意:AMD处理器没有激活PTI补丁,因为他们对 Meltdown攻击免疫,所以如果你在AMD,就不存在性能受到影响的情况。
结果
首先,我们看到所有的性能都有轻微的下降,但是对于具有卷积层的模型的推论却大大减少了。特别是在AlexNet中,正向传递速度下降了大约5%,但是反向传播速度几乎是相同的——这就是为什么训练受到的性能影响大约是推理的一半。
在使用Keras的原始操作方面,完全连接和LSTM层几乎没有性能影响,但是卷积下降了10%。
对于Alexnet和MNIST的基准测试,我使用了TensorFlow教程模型,而对于Keras,我使用了一个随机初始化模型和几个有问题的层,并测量了随机数据的推理速度。值得注意的是,这些基准测试完全在CPU上运行。
TensorFlow教程模型地址:https://github.com/tensorflow/models/tree/master/tutorials/image
我在这里使用Scikit-learn来衡量“经典”机器学习和数据科学算法的性能。在这里,我们看到神经网络性能降低更大,用主成分分析和线性/ 逻辑回归受到的影响可能最大。造成这种减少的原因可能是由于一些数学问题受到了严重的影响——正如下面的NumPy基准所讨论的那样。
有趣的是,KNN完全不受PTI影响,实际上在更新的内核中表现得稍微好一些。这可能只是在误差范围内,但是其他的内核改进可能会稍微加快它的速度。
我还从内存中缓存的文件中提取了一个pandas.read_csv()的基准,以查看PTI降低了多少CSV解析速度 - 阅读博世Kaggle竞争数据集(2GB,1M行,1K列,浮点数, 80%缺失)。
博世Kaggle竞争数据集地址:https://www.kaggle.com/c/bosch-production-line-performance
所有scikit-learn基准都是在博世数据集上计算的——我发现它通常在机器学习基准测试上表现很好,因为它的数据是有大型的、标准化的和格式良好的(尽管KNN和Kmeans是在一个子集上计算的,但完整的数据可能花费的时间太长)。
在这里,这些基准测试可能是合成的,测试单一的scipy操作的速度。这些结果告诉我们,PTI的性能影响是非常依赖于任务的。在这里,我们可以看到,大多数操作仅受到轻微的影响,点积和FFT的性能影响很小。
当PTI启用时,SVD、LU分解和QR分解的性能都受到了巨大的影响,QR分解从190GFLOPS降到110GFLOPS,下降了37%。这可能有助于解释PCA(严重依赖于SVD)和线性回归(严重依赖于QR分解)的性能下降。
这些基准是使用英特尔自己的ibench包完成的——使用了Anaconda,而不是英特尔的python发行版。
ibench包地址:https://github.com/IntelPython/ibench
XGBoost的结果很有趣。在大多数情况下,当使用低数量的线程时,XGBoost在PTI上的性能会下降,无论使用的是慢的精确的方法还是快速直方图方法。
然而,当使用非常多的线程时,CPU同时处理更多的列,使用PTI的速度断崖式降低。
这并不是如何让XGBoost在大量内核上执行的完美表达(因为在12个逻辑内核上运行了40个线程),但是它给出了一个提示:当CPU同时处理许多事情时,PTI会产生更大的影响。不幸的是,我无法访问任何可以修改内核的高内核服务器,因此我无法得到更深入的结果。
和scikit-learn一样,这些基准是在Bosch数据集上管理的。
结论
可以看出,PTI的性能影响是非常依赖于任务的——有些任务是不受影响的,有些任务的性能下降了40%。总的来说,我认为影响比我预期的要小,因为只有少数应用程序受到严重影响。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消