



















神奇!无需数据即可进行机器翻译操作
在日常工作中,深度学习正在被积极地使用。与其他机器学习算法不同的是,深度网络最有用的特性是,随着它获得更多的数据,它们的性能就会有所提高。因此,如果能够获得更多的数据,则可以预见到性能的提高。
深度网络的优势之一就是机器翻译,甚至谷歌翻译现在也在使用它们。在机器翻译中,需要句子水平的并行数据来训练模型,也就是说,对于源语言中的每句话,都需要在目标语言中使用翻译的语言。不难想象为什么会出现这样的问题。因为我们很难获得大量的数据来进行一些语言的配对。
本文是如何构建的?
这篇文章是基于“只使用语料库来进行无监督机器翻译”(Unsupervised Machine Translation Using Monolingual Corpora Only)这篇文章。文章大致遵循了论文的结构。我添加了自己的看法来解释并简化这些内容。此外,这篇文章需要一些关于神经网络的基本知识,如损失函数、自动编码器等。
机器翻译产生问题
如上所述,在机器翻译中使用神经网络产生的最大问题是它需要两种语言的句子对数据集。它适用于像英语和法语这样的广泛使用的语言,但是对于其他的语言来说是不可用的。如果语言对数据可用,这个问题将是一个受监督的任务。
解决方案
文章的作者们想出了如何将这个任务转换成一个无监督的任务。在这个任务中,唯一需要的数据是两种语言的任意两种语料库,例如任意的英语小说VS任意的西班牙语小说。注意,这两本小说内容并不一定是一样的。
在最抽象的意义上,作者发现了如何学习一种介于两种语言之间的潜在空间。
自动编码器
自动编码器是一种广泛的神经网络,在无监督的任务中使用。它们的想法是为了重新创建它们馈送的相同的输入,关键是网络在中间有一个层,叫做瓶颈(bottleneck)层。这个层捕捉所有关于输入的有趣信息,并丢弃无用的信息。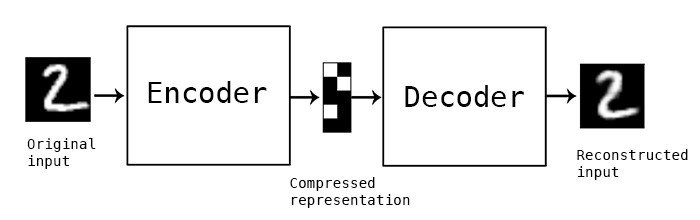
概念上的自动编码器。中间块是存储压缩表示的瓶颈层。
简单地说,输入(现在由编码器转换)位于瓶颈层的空间被称为潜在空间。
降噪自动编码器
如果一个自动编码器被训练要按照它的输入方式重建输入,它可能会学会什么都不做。在这种情况下,输出将得到完美的重建,但是在瓶颈层中我们不会有任何有用的特征。为了解决这个问题,我们使用了降噪的自动编码器。首先,通过添加一些噪声来对实际输入进行轻微的破坏。然后通过网络重建原始图像(而不是噪声版本)。通过这种方式,网络将通过学习噪声(以及真正有用的特征)来学习图像的有用特征。
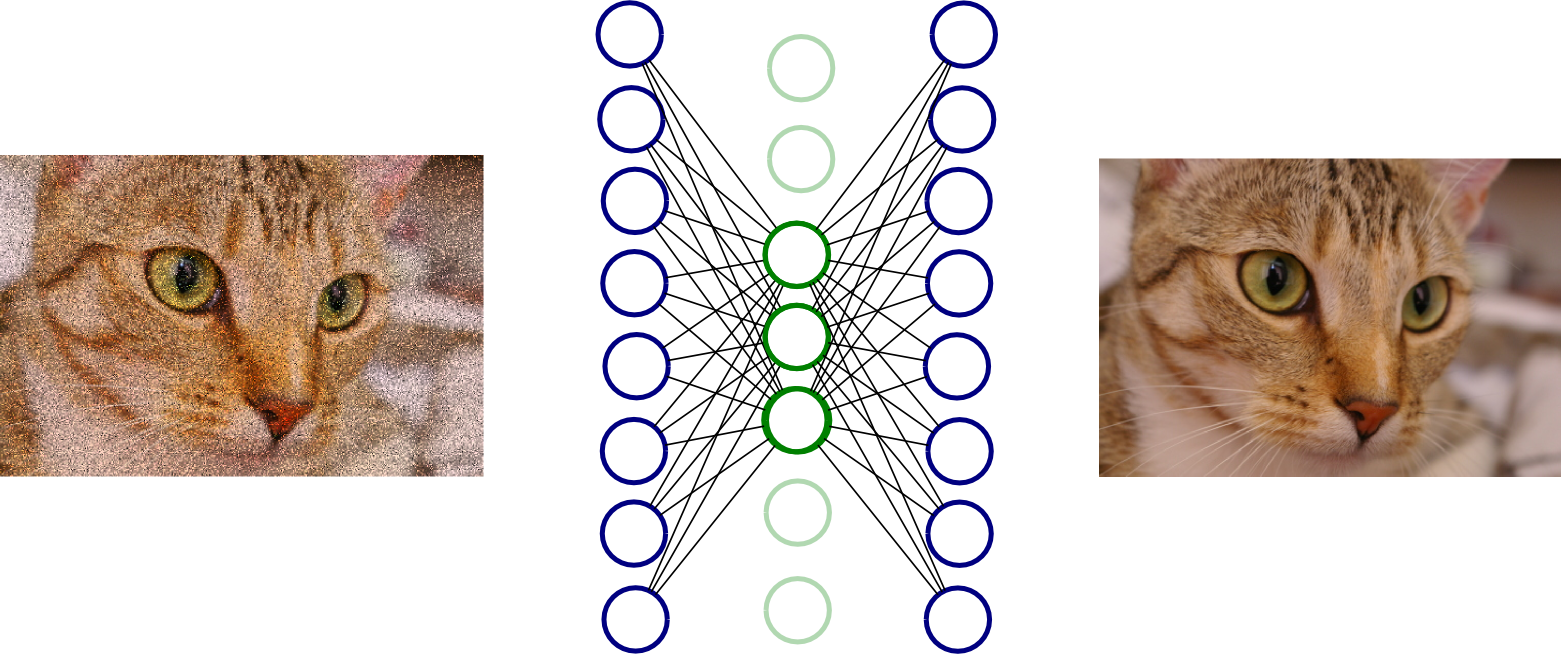
一个降噪的自动编码器的概念示例。左边的图像通过神经网络重建,然后在右边产生图像。在这种情况下,绿色的神经元形成了瓶颈层。
为什么要学习一个共同的潜在空间?
潜在空间捕捉数据的特征(在我们的例子中,数据是句子)。因此,如果有可能学习一个空间,当语言A被馈送给它时,它会产生相同的特征,就像当语言B被馈送给它时一样,它就有可能在它们之间进行转换。由于该模型已经学习了正确的“特征”,从语言A的编码器编码,并且使用语言B的解码器进行解码将会有效地要求它进行翻译。
正如你可能已经猜到的,作者使用了自动编码器来学习一个特征空间。他们还发现了如何使自动编码器学习一个共同的潜在空间(他们称之为一个对齐的(aligned)潜在空间),以便执行无监督的机器翻译。
在语言中的降噪自动编码器
作者使用了一个降噪的编码器,以一种无监督的方式来学习这些特征。他们所定义的损失是: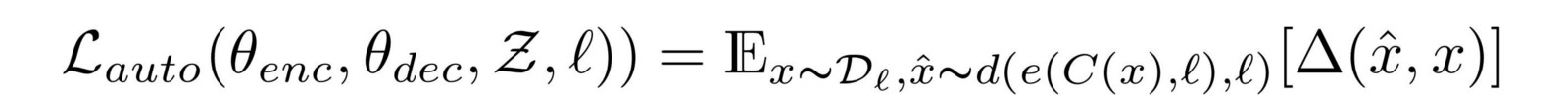
方程1.0降噪自动编码器损失
方程1.0的说明
L是语言(对于这个设置,将有两种可能的语言)。x是输入。C(x)是在给x增加噪声之后的结果,我们很快就会得到噪声创建的函数C。e()是编码器,d()是解码器。最后,Δ(x hat ,x)是令牌(token)级别交叉熵误差的总和。因为我们有一个输入序列,并且我们得到一个输出序列,所以我们需要确保每个令牌都是正确的。因此,这样的损失是被使用的。它可以被认为是一个多标签分类,在输入中的第i个令牌与输出中的第i个令牌进行比较。令牌是一个不能进一步被破坏的单一单元。在我们的例子中,它是一个单词。
因此,方程1.0是一个损失,它将最小化网络的输出(在给定一个噪声输入)和原始的未被改动的句子之间的差异。
和~符号的表示
是表示期望的符号。在这种情况下,它的意思是,输入的分布需要来自于语言L,并且采用损失的平均值。这只是一种数学形式,实际执行过程中的实际损失(交叉熵的总和)将照常执行。
符号~指的是“来自于概率分布”。
如何添加噪声
不像图像,只要把浮点数加到像素上就可以增加噪声,在语言中添加噪声就需要不同的方法。因此,作者们开发了他们自己的系统来制造噪声。他们用C()表示它们的噪声函数。它接收输入句子,并且输出这个句子的噪声版本。
有两种不同的方法来添加噪声。首先,可以简单地从输入中删除一个单词,并使用一个P_wd的概率。第二,每个单词都可以从原来的位置改变。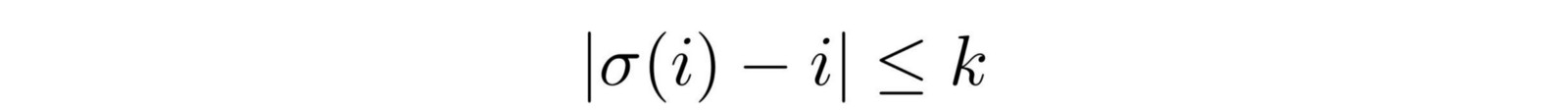
这里,σ表示第i个令牌移动的位置。因此,方程2.0表示:“一个令牌可以从大多数k个令牌移动到左边或右边。”
作者使用的k值为3,而P_wd值为1。
跨域训练
为了学习如何在两种语言之间进行转换,这有一些过程将输入句(在语言A)映射到输出句(在语言B中),作者称之为跨域训练。首先,对输入句(x)进行取样。然后,通过使用前一次迭代中的模型(M())来生成翻译输出(y)。把它放在一起,就得到y=M(x)。在此之后,使用上面描述的相同的噪声函数C(),y被破坏了,并给出了C(y)。语言A的编码器被用来编码这个被破坏的版本,而语言B的解码器被用来解码来自语言A的编码器的输出,并重新创建一个干净版本的C(y)。这些模型使用的是与方程式1.0相同的交叉熵误差的训练。
通过对抗训练来学习一个共同的潜在空间
到目前为止,本文还没有提到如何学习共同的潜在空间。上面提到的交叉领域训练可能有助于学习类似的空间,但是需要更强的约束来推动模型学习类似的潜在空间。作者使用了对抗性的训练。他们使用另一个模型(称为鉴别器),它接收每个编码器的输出,并预测被编码的句子属于哪一种语言。然后,采用了鉴别器的梯度,并对编码器进行了训练,以欺骗鉴别器。这在概念上与标准的GAN(生成对抗网络)没有什么不同。鉴别器接收每一个时间步长的特征向量(因为使用了递归神经网络),并预测它来自哪种语言。
把它聚集到一起
上面提到的3种不同的损失(自动编码器损失、翻译损失和鉴别器损失)被加在一起,所有的模型权重都在一个步骤中更新。
由于这是序列问题的一个序列,作者使用了LSTM网络,注意,也就是说,有两个基于LSTM的自动编码程序,每个语言都有一个。
在高层次上,有三个主要的步骤来训练这个架构。它遵循一个迭代的训练过程。训练的循环过程:
1.使用语言A的编码器和语言B的解码器来获得翻译
2.训练每一个自动编码器,以使一个未被破坏的句子重新生成一个被损坏的句子
3.通过对步骤1中获得的翻译进行破坏来改进译文,并重新创建它。在这个步骤中,语言A的编码器和语言B的解码器是一起训练的(同时也是语言B的编码器和语言A的解码器)。
注意,尽管步骤2和3是单独列出的,但是它们的权重都被更新了。
如何快速启动这个框架
正如上面所提到的,该模型使用了来自前一个迭代的它自己的翻译来改进其翻译能力。因此,在训练开始之前,有一定的翻译能力是很重要的。作者使用FastText学习了具备单词水平的双语词典。注意,这种方法非常简单,只需要给模型一个起点。整个框架在下面的流程图中给出: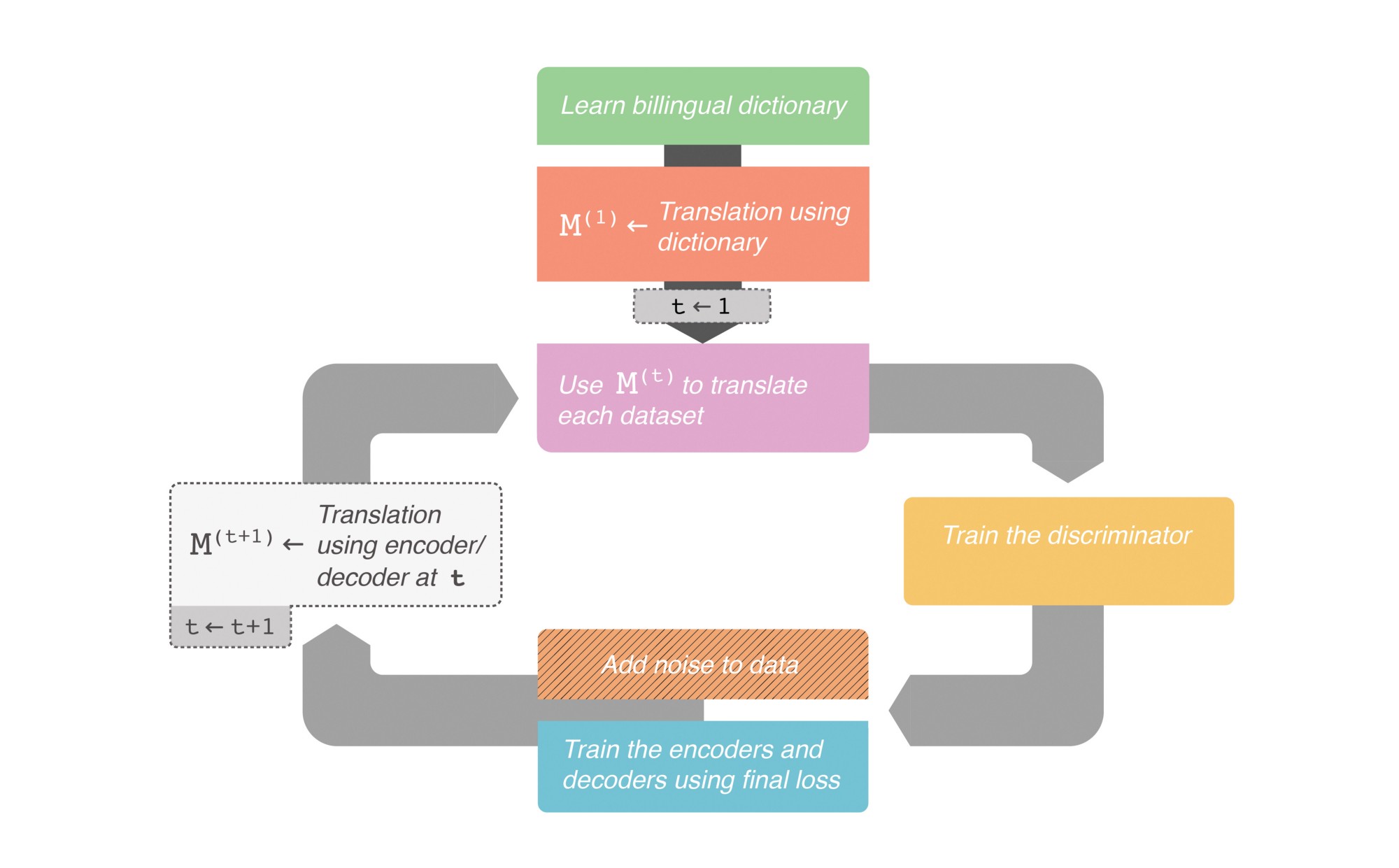
整个翻译框架的高水平工作
结论
这是对一种新技术的解释,它可以执行无监督的机器翻译。此外,它使用了多种不同的损失来改进单个任务,同时使用对抗性的训练来增加对架构行为的约束。









