


















一文教你实现skip-gram模型,训练并可视化词向量
在本教程中,我将展示如何在Tensorflow中实现一个Word2Vec(Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理中)的skip-gram模型,为你正在使用的任何文本生成词向量,然后使用Tensorboard将它们可视化。
我在text8数据集上训练了一个skip-gram模型。然后,我用Tensorboard来设想这些Embedding,Embedding其实就是一个映射,将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。Tensorboard允许你通过使用PCA选择3个主轴来投射数据,从而查看整个词云(world cloud)。你可以输入任何一个单词,它就会显示它的相邻的词语。你也可以把离它最近的101个点分离出来。请观看下面的动图:
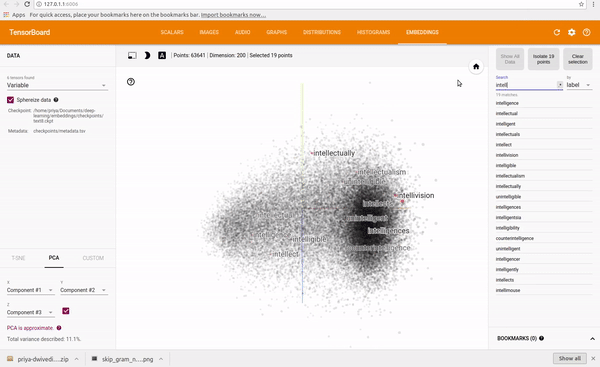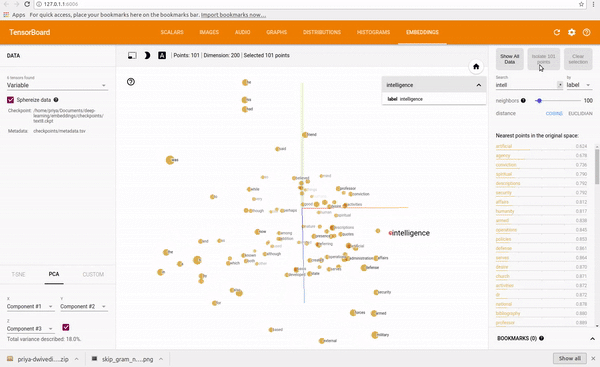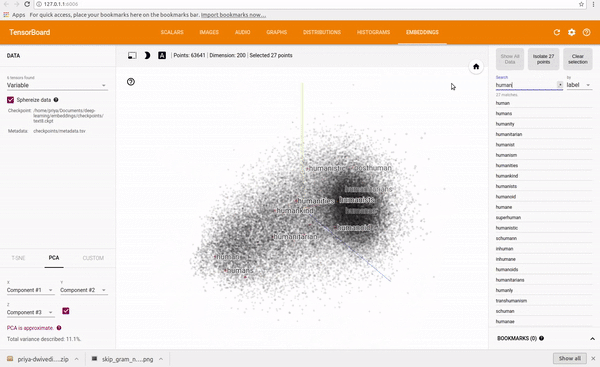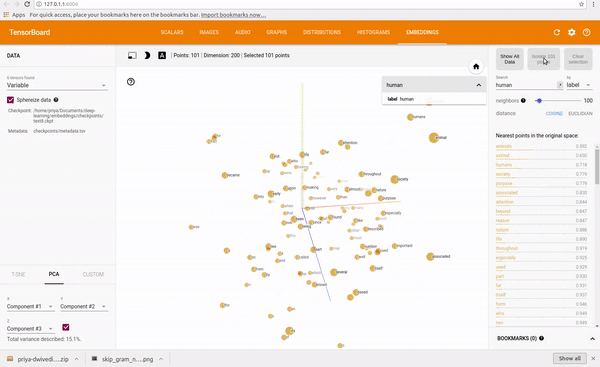
为了可视化训练,我还研究了最接近预测的单词,并将其与一组随机的单词进行了比较。在第一次迭代中最接近的预测词看起来很随意,但这却很有意义,因为所有的词向量都是随机初始化的。
Nearest to cost: sensationalism, adversity, ldp, durians, hennepin, expound, skylark, wolfowitz,
Nearest to engine: vdash, alloys, fsb, seafaring, tundra, frot, arsenic, invalidate,
Nearest to construction: dolphins, camels, quantifier, hellenes, accents, contemporary, colm, cyprian,
Nearest to http: internally, chaffee, avoid, oilers, mystic, chappell, vascones, cruciger,
在训练结束的时候,这个模型在寻找单词之间的关系方面变得更好了。
Nearest to cost: expense, expensive, purchase, technologies, inconsistent, part, dollars, commercial,
Nearest to engine: engines, combustion, piston, stroke, exhaust, cylinder, jet, thrust,
Nearest to construction: completed, constructed, bridge, tourism, built, materials, building, designed,
Nearest to http: www, htm, com, edu, html, org, php, ac,
CBOW模型和Skip-gram模型
创建词向量是指获取大量文本的过程,并为每个单词创建一个向量,这样在语料库中共享公共上下文的词就位于向量空间中彼此相邻的位置。
这些单词向量可以很好地捕捉单词之间的上下文关系(例如,黑色、白色和红色的示例向量是紧密联系在一起的),我们使用这些向量来获得更好的性能,而不是像文本分类或新文本生成这样的自然语言处理任务。
有两个主要的模型可以生成这些词向量——CBOW模型和skip-gram模型。CBOW模型尝试预测给定上下文词的中心词,而skip-gram模型试图预测给定中心词的上下文词。下面有一个简单的例子:
CBOW:猫吃了___。填充空白,在这种情况下中,空白处应为“食物”。
Skip-gram:___ ___食物。完成单词“食物”的上文。在这种情况下,空白处应为"猫吃了"
各种各样的论文都发现Skip-gram模型会产生更好的词向量,所以我准备把重点放在实现Skip-gram模型上。
在Tensorflow中实现Skip-gram模型
在这里,我将列出构建模型的主要步骤。详细实现过程请参阅:https://github.com/priya-dwivedi/Deep-Learning/blob/master/word2vec_skipgram/Skip-Grams-Solution.ipynb
1.预处理数据
首先要清洗我们的数据。删除任何标点、数字,并将文本拆分为单个单词。由于程序对整数的处理要比单词好得多,所以我们通过创建一个单词到int字典来将每个单词映射到int。代码如下:
counts = collections.Counter(words)
vocab = sorted(counts, key=counts.get, reverse=True)
vocab_to_int = {word: ii for ii, word in enumerate(vocab, 0)}
2.二次抽样(Subsampling)
经常出现的词语,如“我的”、“你的”和“他的”,无法给附近的单词提供太多的上下文信息。如果我们放弃其中的一些单词,我们就可以从我们的数据中移除一些噪声(noise),以得到更快的训练和更好的表现。这一过程被称为“二次抽样”(详细内容请看下面链接)。对于训练集里的每一个单词,我们将用它的相反的频率丢弃它。
3.创建输入和目标
Skip-gram模型的输入是每个单词(编码为int),目标是窗口(window)周围的单词。如果这个窗口的大小是可变的,那么更频繁地对中心词进行采样的话,性能会更好。
“因为较远的词通常不与当前词相关,所以通过从我们训练样本中的这些词汇给较远距离的词少量的权重…如果我们将窗口大小(window size)设置为5,那么对于每个训练的单词我们将随机选择一个1到窗口大小(5)之间的数字R,然后使用当前词的R个历史单词和R个未来单词作为正确的标签。”
R = np.random.randint(1, window_size+1)
start = idx — R if (idx — R) > 0 else 0
stop = idx + R
target_words = set(words[start:idx] + words[idx+1:stop+1])
4.构建模型
从下面博客中,我们可以看到我们将要构建的一般结构的网络。
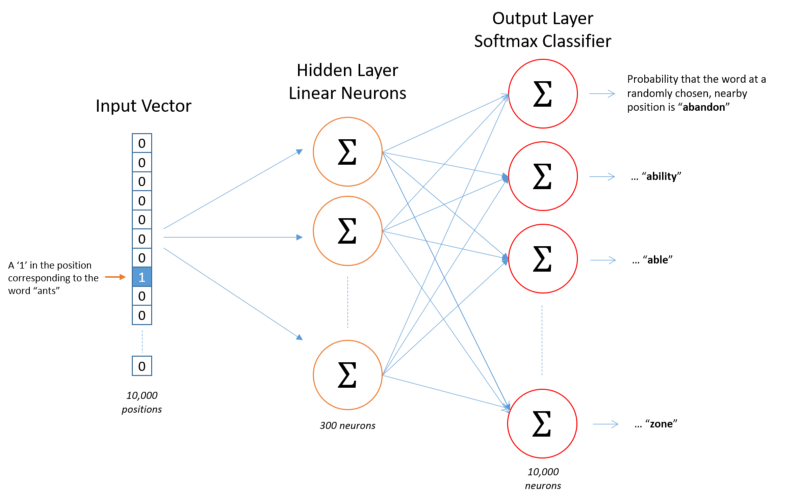 我们将表示一个像“ants”这样的输入词,它是一个独热向量。这个向量将有10,000个组件(一个用于我们的词汇表中的每个单词),我们将在这个位置放置一个“1”,对应于“ants”这个词0。
我们将表示一个像“ants”这样的输入词,它是一个独热向量。这个向量将有10,000个组件(一个用于我们的词汇表中的每个单词),我们将在这个位置放置一个“1”,对应于“ants”这个词0。网络的输出是一个单一的向量(也包含10,000个组件),对于我们词汇表中的每个词来说,随机选择临近单词的概率是字汇词(vocabulary word)。
在训练的最后,隐藏层将会有训练过的词向量。隐藏层的大小对应于向量中空间的数量。在上面的例子中,每个单词都有一个长度为300的向量。
你可能已经注意到,Skip-gram神经网络包含了大量的权重。对于我们的例子来说,如果我们现在想用300个特征来表示一个单词(即每个词可以被表示为300维的向量)。那么隐层的权重矩阵应该为10000行,300列(隐层有300个结点)。在大型数据集上进行训练是不可能的,因此word2vec的作者引入了一些调整,使训练变得可行。详情如下:
5.可视化使用Tensorboard
你可以使用Tensorboard上的embeddings projector来可视化嵌入。要做到这一点,你需要做以下几件事:
- 在检查点(checkpoint)目录的训练结束时保存你的模型
- 创建一个元数据tsv文件,它将每个int的映射回到单词上,这样,Tensorboard将显示单词而不是ints。在相同的检查点目录中保存这个tsv文件
- 运行这段代码:
from tensorflow.contrib.tensorboard.plugins import projector
summary_writer = tf.summary.FileWriter(‘checkpoints’, sess.graph)
config = projector.ProjectorConfig()
embedding_conf = config.embeddings.add()
# embedding_conf.tensor_name = ‘embedding:0’
embedding_conf.metadata_path = os.path.join(‘checkpoints’, ‘metadata.tsv’)
projector.visualize_embeddings(summary_writer, config)









