












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






强化学习系列(上):关于强化学习,你需要知道的重要知识点
2017年11月14日 由 yining 发表
116146
0
强化学习是一个非常有用的工具,可以在任何机器学习工具包中使用。为了能使你能够尽可能快地实现最新的模型,本系列的两篇文章是作为基础知识来设计的。这两篇文章中将分享强化学习中最重要的知识点。在文章的最后,你将了解所有的基本理论,以理解强化学习算法是如何工作的。首先我们看看本系列的上半部分内容。
监督学习 VS 评估学习
对于许多感兴趣的问题,监督学习的范例并没有给我们带来我们所需要的灵活性。监督学习与强化学习之间的主要区别在于,所获得的反馈是否具有评估性(evaluative)或启发性(instructive)。有启发意义的反馈告诉你如何实现你的目标,而评估反馈则告诉你你的目标有多好。监督学习是基于有启发意义的反馈来解决问题的,而强化学习则是基于评估的反馈来解决问题的。图像分类是一个有启发反馈的监督问题;当算法试图对某一数据进行分类时,它会被告知真正的类是什么。另一方面,评估反馈只是告诉你你在实现目标方面做得多好。如果你用评估反馈训练一个分类器,你的分类器可能会说“我认为这是一只仓鼠”,作为回报,分类器将得到50分的反馈分数。我们也不清楚50分算是怎样程度,也许10000分是一个更棒的分数,但直到我们尝试对其他数据点进行分类之前,我们都不知道是否如此。
在许多问题中,评估反馈的想法更直观,更容易理解。例如,想象一个控制数据中心温度的系统。有启发性的反馈似乎没有多大意义,任何给定的时间步长中,你如何告诉你的算法在每个组件的正确设置是什么? 评估的反馈更有意义。因为你可以很容易地反馈数据,比如在某个时间段内使用了多少电,或者平均温度是多少。这实际上就是谷歌如何使用强化学习解决问题的办法。因此,让我们看看到底什么是强化学习。
马尔可夫决策过程
假定我们知道状态s,如果未来的状态条件不依赖于过去的状态,那么状态s符合马尔可夫属性。这意味着状态s描述了所有过去直至当前的状态。如果你还是不理解这个决策过程的话,那么通过一个示例就可以更容易地理解它:考虑一个球在空中飞行。如果它的状态s是由它的位置p和速度v决定的,那就足以描述它目前的位置和它将要去的地方(假设给定条件是一个物理模型,并且没有外部影响)。然而,如果我们只知道球的位置,而不知道它的速度,它的状态就不再是具有马尔可夫性。目前的状态并没有总结过去所有的状态,我们需要从之前的步骤中得到的信息来开始构建一个正确的球的模型。
强化学习通常被建模为马尔可夫决策过程,即MDP。MDP是一种有向图,它的节点和边缘描述了马尔可夫状态之间的过渡。这里有一个简单的例子: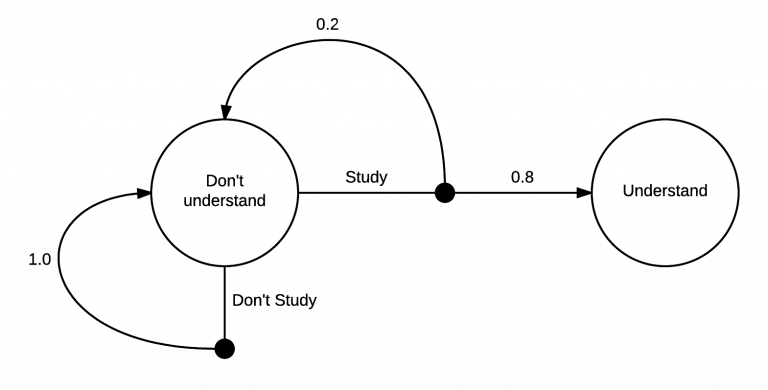 上面这张图解释了马尔可夫决策的学习过程:一开始,你在“不理解”的状态中。从那里,你有两种可能的行为,“学习”或“不学习”。如果你选择“不学习”,你有100%的可能会回到“不理解”的状态。然而,如果你选择“学习”,你有20%的可能性回到你最初的“不理解”状态,但是有80%的机会最终进入“理解”状态。
上面这张图解释了马尔可夫决策的学习过程:一开始,你在“不理解”的状态中。从那里,你有两种可能的行为,“学习”或“不学习”。如果你选择“不学习”,你有100%的可能会回到“不理解”的状态。然而,如果你选择“学习”,你有20%的可能性回到你最初的“不理解”状态,但是有80%的机会最终进入“理解”状态。
实际上,我相信过渡到“理解”状态的几率要比80%高很多,马尔可夫决策的核心部分真的非常简单。从一个状态开始,你可以采取一系列的行动。在你采取行动之后,你可以决定在哪些状态下过渡到你的状态。在“不学习”行为的情况下,这种转变也很有可能是决定性的。
强化学习的目标是学习如何在更有价值的状态中花费更多的时间。要有一个有价值的状态,我们需要在马尔可夫决策中有更多的信息。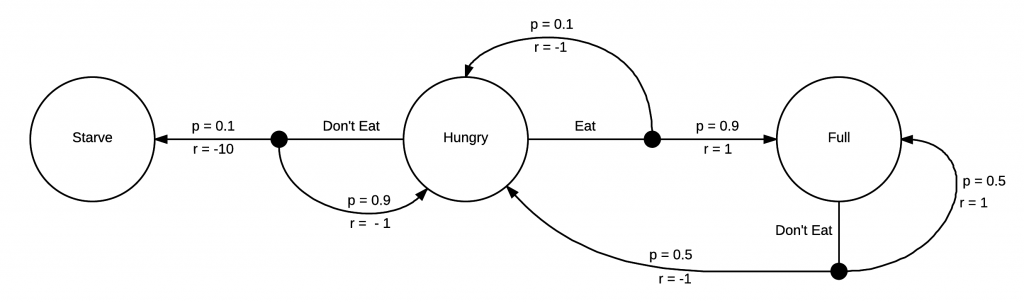 你不需要用一个马尔可夫决策教你“不吃东西”会让你“挨饿”。不过,强化学习agent可能会需要。
你不需要用一个马尔可夫决策教你“不吃东西”会让你“挨饿”。不过,强化学习agent可能会需要。
这个马尔可夫决策有附加的回报r。每次你向一个状态过渡时,你都会得到回报。在这个例子中,你会因为“饥饿”的状态而得到负面的回报,而对于“饿死”的人来说,这是一个巨大的负面回报。然而,如果你是“吃饱”的状态的话,你就会得到一个正面的回报。既然我们的马尔可夫决策已经完全成形了,我们就可以开始考虑如何采取行动来获得最大的回报!
因为马尔可夫决策很简单,我们很容易就能看到,当我们饿的时候,我们就可以在更高回报的地方吃东西。我们没有太多的选择,当我们在模型中的状态为“吃饱”的时候,我们就会有更多的选择,但是我们将不可避免地再次“挨饿”,并且接下来立即选择“吃东西”这种行为。
将强化学习问题正式化
现在我们有了许多我们需要的构建块,然后我们应该看看强化学习中使用的术语。最重要的组成是agent和环境。一个agent存在于某些有间接控制的环境中。通过回顾我们的马尔可夫决策,agent可以选择在给定状态下采取哪些操作,这对所看到的状态有很大的影响。但是,agent并不能完全控制环境的动态。因为环境在接收到这些动作后,会返回到新的状态和回报中。
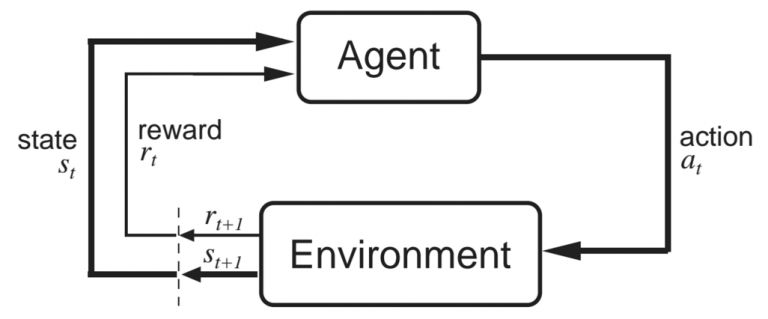
上面这张图片是来自Sutton和Barto的“强化学习:介绍”这本书(强烈推荐),它解释了agent和环境的相互作用。在某一时时间步长中,agent在状态st中,并采取行动at。然后环境以新的状态st+1和回报rt+1进行响应。回报在t+1上的原因是因为它是在状态st+1的环境中返回的,所以让它们保持一致是有意义的(就像图像中显示的那样)。
结论
我们现在有了一个关于强化学习问题的框架,并且准备好开始考虑如何最大化我们的回报。在下一篇文章中,我们将学习状态值函数和动作值函数,以及贝尔曼方程,它为解决强化学习问题的算法奠定了基础。我们还将探索一些简单而有效的动态规划解决方案。
监督学习 VS 评估学习
对于许多感兴趣的问题,监督学习的范例并没有给我们带来我们所需要的灵活性。监督学习与强化学习之间的主要区别在于,所获得的反馈是否具有评估性(evaluative)或启发性(instructive)。有启发意义的反馈告诉你如何实现你的目标,而评估反馈则告诉你你的目标有多好。监督学习是基于有启发意义的反馈来解决问题的,而强化学习则是基于评估的反馈来解决问题的。图像分类是一个有启发反馈的监督问题;当算法试图对某一数据进行分类时,它会被告知真正的类是什么。另一方面,评估反馈只是告诉你你在实现目标方面做得多好。如果你用评估反馈训练一个分类器,你的分类器可能会说“我认为这是一只仓鼠”,作为回报,分类器将得到50分的反馈分数。我们也不清楚50分算是怎样程度,也许10000分是一个更棒的分数,但直到我们尝试对其他数据点进行分类之前,我们都不知道是否如此。
在许多问题中,评估反馈的想法更直观,更容易理解。例如,想象一个控制数据中心温度的系统。有启发性的反馈似乎没有多大意义,任何给定的时间步长中,你如何告诉你的算法在每个组件的正确设置是什么? 评估的反馈更有意义。因为你可以很容易地反馈数据,比如在某个时间段内使用了多少电,或者平均温度是多少。这实际上就是谷歌如何使用强化学习解决问题的办法。因此,让我们看看到底什么是强化学习。
马尔可夫决策过程
假定我们知道状态s,如果未来的状态条件不依赖于过去的状态,那么状态s符合马尔可夫属性。这意味着状态s描述了所有过去直至当前的状态。如果你还是不理解这个决策过程的话,那么通过一个示例就可以更容易地理解它:考虑一个球在空中飞行。如果它的状态s是由它的位置p和速度v决定的,那就足以描述它目前的位置和它将要去的地方(假设给定条件是一个物理模型,并且没有外部影响)。然而,如果我们只知道球的位置,而不知道它的速度,它的状态就不再是具有马尔可夫性。目前的状态并没有总结过去所有的状态,我们需要从之前的步骤中得到的信息来开始构建一个正确的球的模型。
强化学习通常被建模为马尔可夫决策过程,即MDP。MDP是一种有向图,它的节点和边缘描述了马尔可夫状态之间的过渡。这里有一个简单的例子:
上面这张图解释了马尔可夫决策的学习过程:一开始,你在“不理解”的状态中。从那里,你有两种可能的行为,“学习”或“不学习”。如果你选择“不学习”,你有100%的可能会回到“不理解”的状态。然而,如果你选择“学习”,你有20%的可能性回到你最初的“不理解”状态,但是有80%的机会最终进入“理解”状态。实际上,我相信过渡到“理解”状态的几率要比80%高很多,马尔可夫决策的核心部分真的非常简单。从一个状态开始,你可以采取一系列的行动。在你采取行动之后,你可以决定在哪些状态下过渡到你的状态。在“不学习”行为的情况下,这种转变也很有可能是决定性的。
强化学习的目标是学习如何在更有价值的状态中花费更多的时间。要有一个有价值的状态,我们需要在马尔可夫决策中有更多的信息。
你不需要用一个马尔可夫决策教你“不吃东西”会让你“挨饿”。不过,强化学习agent可能会需要。这个马尔可夫决策有附加的回报r。每次你向一个状态过渡时,你都会得到回报。在这个例子中,你会因为“饥饿”的状态而得到负面的回报,而对于“饿死”的人来说,这是一个巨大的负面回报。然而,如果你是“吃饱”的状态的话,你就会得到一个正面的回报。既然我们的马尔可夫决策已经完全成形了,我们就可以开始考虑如何采取行动来获得最大的回报!
因为马尔可夫决策很简单,我们很容易就能看到,当我们饿的时候,我们就可以在更高回报的地方吃东西。我们没有太多的选择,当我们在模型中的状态为“吃饱”的时候,我们就会有更多的选择,但是我们将不可避免地再次“挨饿”,并且接下来立即选择“吃东西”这种行为。
将强化学习问题正式化
现在我们有了许多我们需要的构建块,然后我们应该看看强化学习中使用的术语。最重要的组成是agent和环境。一个agent存在于某些有间接控制的环境中。通过回顾我们的马尔可夫决策,agent可以选择在给定状态下采取哪些操作,这对所看到的状态有很大的影响。但是,agent并不能完全控制环境的动态。因为环境在接收到这些动作后,会返回到新的状态和回报中。
上面这张图片是来自Sutton和Barto的“强化学习:介绍”这本书(强烈推荐),它解释了agent和环境的相互作用。在某一时时间步长中,agent在状态st中,并采取行动at。然后环境以新的状态st+1和回报rt+1进行响应。回报在t+1上的原因是因为它是在状态st+1的环境中返回的,所以让它们保持一致是有意义的(就像图像中显示的那样)。
结论
我们现在有了一个关于强化学习问题的框架,并且准备好开始考虑如何最大化我们的回报。在下一篇文章中,我们将学习状态值函数和动作值函数,以及贝尔曼方程,它为解决强化学习问题的算法奠定了基础。我们还将探索一些简单而有效的动态规划解决方案。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消